






HTML
-
为了提升公共生活和资产的安全性,视频监视系统已经广泛部署于商场、医院、银行、街道、教育机构,城市行政办公室和智慧城市等公共场所中。在大多数情况下,如何及时、准确地检测视频异常事件是社会公共安全风险防控的主要目标。视频异常事件定义为视频中不符合正常模式的异常或不规则模式。这些事件往往包括打架、骚乱、违反交通规则、踩踏、持械以及遗弃行李等行为。近年来,异常事件检测已经逐渐成为计算机视觉和模式识别领域的研究热点,其主要难点是异常定义的模糊性,异常数据的稀少性,以及复杂的环境背景和人类行为。
概括地说,当前有关视频异常检测的大多数研究工作可以分为两个步骤,例如特征提取和正常模型训练[1]。特征提取可以通过手工技术或自动特征提取技术(表示学习或基于深度学习的特征)来实现。在正常模型训练则是采用正常样本进行学习,然后将不符合所学习模型的样本判定为异常事件。那么,按照特征进行分类可以分为3类不同的方法[2]:(1)基于轨迹的方法[3]:这类方法通过对目标进行跟踪以获取轨迹特征,但是在密集场景对目标跟踪是一大难题;(2)基于全局特征的方法[4-5]:这类方法将视频帧作为一个整体,提取一些底层或者中层特征如时空梯度、光流等,在中等拥挤和密集环境中均有效;(3)基于网格特征的方法[6]:这类方法往往通过密集采样将视频帧划分为多个小网格,然后对单个网格提取底层特征,因为每个网格都可以单独被评价。按照采用不同的正常模型训练方式,也可以分为3种不同的方法:(1)基于聚类的方法[7]:这类方法往往基于一个假设,正常样本属于一个类别或者距离聚类中心较近,而异常样本则不属于任何类别或者远离聚类中心,然后针对正常样本进行聚类以建立模型;(2)基于稀疏重构的方法[8-9]:这类方法假设是,正常模式的稀疏线性组合能够以最小的重构误差表示正常活动,而由于训练数据集中不存在异常活动,因此能够以较大的重构误差表示异常模式;(3)基于概率模型的方法[10]:这种方法认为正常样本符合某个概率分布,而异常样本则不符合该分布。
近期,深度学习的最新进展证明了基于深度学习的方法在许多计算机视觉应用中的明显优势[11]。作为计算机视觉中的任务之一,视频异常检测也不例外。与传统基于手工特征方法不同的是,深度学习方法往往采用预训练网络对视频进行高层的特征提取,或者直接根据正常模型采用现有网络结构建立端对端的异常检测模型。对于前一种思路[12-13],和传统的异常事件检测两个步骤没有太多差别。而对于后一种思路[14-19],特征提取和模型建立两个步骤往往是在一个深度网络中联合优化的,因为能够实现二者最优,这也是深度学习方法的一大优势。这些端对端的深度网络包括深度自编码(Auto-Encoder, AE)、深度孪生网络(Deep Siamese Network, DSN)、生成对抗网络(Generative Adversarial Nets,GAN)[15,20-24]。然而,这些网络模型往往是针对其他任务如生成模型、压缩等,不是针对异常检测任务而单独设计的。
文中在深度学习的框架下,面向异常检测任务,基于深度支持向量数据描述(Deep Support Vector Data Description, DSVDD),提出一种新的异常检测方法。通过学习DSVDD,能够找到建立SVDD的最小数据超球面,并且以获得输入数据的特征表示并且学习得到正常模型。为此,DSVDD采用了经过联合训练的深度神经网络,将正常样本数据映射到最小体积的超球中。那么在测试时,映射在超球面内的样本被判别为正常,而映射在超球面外的样例判别为异常。文中方法将RGB图和光流图组成一个6通道数据直接输入到一个DSVDD模型中,即能同时检测外观异常和运动异常。在Avenue[9]和ShanghaiTec[21]两个公开数据集上的实验结果表明,文中提出的方法检测效果优异,超过现有技术发展水平。
-
文中所提出的方法总流程如图1所示。在训练阶段,训练样本的RGB图像和光流图被密集采样,然后合并成一个6通道的数据,训练深度支持向量数据描述模型;在测试阶段,同样获得待测视频帧的RGB图像和光流图组成的6通道数据,输入到学习好的深度支持向量数据描述模型后,判定该区域是否异常。在本节中,首先简要介绍支持向量数据描述原理,然后在此基础上重点描述基于深度支持向量数据描述的视频异常事件训练和测试过程。
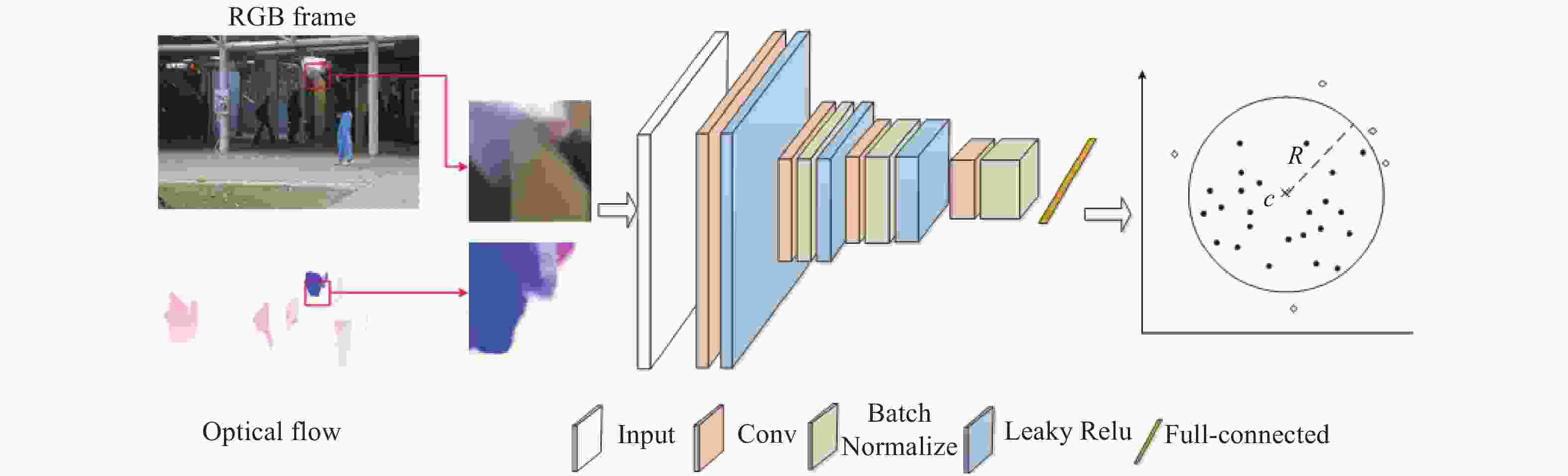
Figure 1. The flow chart of video anomaly detection based on DSVDD
-
支持向量数据描述(Support Vector Data Description, SVDD)是一种基于边界数据(支持向量)的描述方法,其目标是寻求一个包含所有或几乎所有的训练样本且体积最小的超球体(中心为
$\boldsymbol{c} \in {{F}_k}$ 和半径为$R > 0$ )。实际上,SVDD优化问题可以转化为:式中:松弛变量
${\xi _i} \geqslant 0$ 允许一个软边界和超参数$v \in \left. {\left( {0,1} \right.} \right]$ 控制着惩罚项与超球的体积边之间的平衡。因此,落到超球面外的点,例如$\left\| {{\phi _k}\left( {{{x}_i}} \right) - {c}} \right\|_{{{F}_k}}^2 > {R^2}$ ,则判断注定是异常的。SVDD已被广泛应用于异常检测、人脸识别、语音识别、图像恢复和医学成像等领域[19]。 -
DSVDD通过学习一个权值为
${W}$ 的深度神经网络$ \varphi \left( \cdot ;{W}\right)$ ,使得输入的正常样本空间${X} \subseteq {{R}^d}$ 能够映射到一个中心为$\boldsymbol{c}$ 和半径为$R$ 最小超球面,正常样例的映射在超球面内,而异常样例的映射在超球面外。具体来说,对于样本区域输入空间
${X} \subseteq {\mathbb{R}^d}$ 和输出空间${F} \subseteq {\mathbb{R}^p}$ ,采用一个包含$L \in \mathbb{N}$ 个隐藏层的神经网络能够将输入空间投影到输出空间${X} \to {F}$ ,其中${W}{\rm{ = }}\left\{ {{{W}^1},{{W}^2}, \cdots ,{{W}^L}} \right\}$ 分别是隐藏层$\ell {\rm{ = }}\left\{ {1,2, \cdots ,L} \right\}$ 的权值。因此,$\phi \left( {{x};{W}} \right) \in {F}$ 是输入样本$\boldsymbol{x} \in {X}$ 在神经网络$\phi $ 下的特征表示,那么DSVDD方法的目标就是联合优化网络权值${W}$ 和输出空间符合中心为$\boldsymbol{c}$ 和半径为R最小超球面约束。那么,给定训练样本${{D}_n} =\{ {{{x}_1},{{x}_2}, \cdots ,} $ $ {{{x}_n}} \}$ ,DSVDD的软边界目标函数为:对于公式(2)来说,在SVDD方法中,最小化R2表示最小化超球的体积。第二项是通过神经网络进行映射到超球外的惩罚项,例如那些距离超球中心
$\left\| {\phi \left( {{{x}_i};{W}} \right) - c} \right\|$ 大于半径R的样本。超参数$v \in \left. {\left( {0,1} \right.} \right]$ 控制着超球的体积与边界的偏离之间的平衡,即允许将某些点映射到球体外部。最后一项是网络参数权值${W}$ 衰减的正则化项,其中$\lambda > 0$ ,且${\left\| \cdot \right\|_F}$ 表示Frobenius范数。对于公式(2)的优化使得网络能够学习权值
${W}$ ,使得数据点能够紧密地投影到超球中心$\boldsymbol{c}$ 附近。为此,深度网络必须提取数据变化的共同因素。实际上,正常样本往往能够紧密映射到超球中心$\boldsymbol{c}$ 附近,而异常样本则被映射到更远离中心或超球面之外。通过这种方式获得了对正常模型的紧凑描述。在实际任务中,往往假设训练样本
${{D}_n}$ 均为正常样本,那么目标函数可以简化为一个单类分类问题如下:此时,DSVDD简单地采用二次损失来惩罚每个深度网络表示
$\phi \left( {{{x}_i};{W}} \right)$ 到$\boldsymbol{c}$ 的距离。第二项是网络参数权值${W}$ 衰减的正则化项,$\lambda > 0$ 。公式(3)也可以看成是以中心$\boldsymbol{c}$ 为中心找到最小体积的超球面。但是和公式(2)采用软边界不同,公式(3)通过最小化所有数据表示到中心的平均距离来收缩球体,而不是通过直接惩罚半径和落在球体之外的数据表示来收缩。同样,为了将样本映射到尽可能靠近超球中心$c$ 的位置,深度神经网络必须提取变化的公共因子。可以通过常见的反向传播方法(例如随机梯度下降法)优化DSVDD中神经网络的权值
${W}$ 。由于网络权值${W}$ 和超球半径R尺度不同,采用一种学习率无法优化DSVDD。因此,需要以交替最小化/块坐标下降法交替优化网络权值${W}$ 和超球半径R。具体来说,首先把超球半径R固定,迭代$k$ 次训练神经网络权值${W}$ ,然后再通过线搜索求解超球半径R,这样接替迭代,具体过程可以参考文献[20]。 -
给定测试样本区域
$\boldsymbol{x}' \in {X}$ ,可以根据其通过神经网络$\phi \left( {{x}';{{W}^{\rm{*}}}} \right)$ 后到超球中心$\boldsymbol{c}$ 的距离计算异常得分:式中:
${{W}^{\rm{*}}}$ 为已训练好的网络模型参数。值得注意的是,网络参数能够使${{W}^{\rm{*}}}$ 完全表征DSVDD模型,并且无需存储任何数据即可进行预测,因此DSVDD具有非常低的存储复杂度,测试时计算复杂度较小。为了推断测试样本区域的是否为异常样本,可以通过对
$s\left( {{x}'} \right)$ 设定阈值来进行判断:式中:
$\theta $ 为决定文中检测方法的敏感度的阈值。
1.1. 支持向量数据描述





1.2. 深度支持向量数据描述






































1.3. 测 试







-
文中在两个公开的数据集上评估了DSVDD方法的性能,它们分别是:Avenue数据集[9]和ShanghaiTech数据集[21]。Avenue数据集是用于视频异常检测的最广泛使用的基准之一。它包含16个训练视频片段和21个测试视频片段,其中有47个在香港中文大学街道上发生的异常事件。每个视频长约1 min,分辨率为640×360。正常事件是在街道上行走,异常事件包括奔跑、游荡和投掷等。ShanghaiTech Campus数据集[21]是新提出的用于视频异常检测的最大数据集之一。与其他数据集不同,在该数据集中视频剪辑来自13个不同的摄像机,这些摄像机具有不同的照明条件和摄像机角度。它有330个训练视频片段和107个包含130个异常事件的测试视频片段。视频帧的分辨率为856×480。该数据集中异常事件包括追逐和吵闹等。
-
根据先前的工作[15],文中计算帧级接收器工作特性(ROC)曲线,并使用曲线下的面积(AUC)分数作为评估指标,较高的AUC分数表示更好的异常检测性能。若视频帧中有一个区域判断为异常,则该帧判断为异常。课题组首先获得所有视频帧的异常分数,然后计算帧级AUC分数。
-
对于两个数据集,每帧都被调整为大小320×240,光流图像由参考文献[22]中提供的RAFT光流法通过在things数据集上预训练的网络计算得到。将原始视频帧和计算获得的光流图合并成一个6通道的数据,然后按照尺寸20×20的大小裁剪为16×12个网格图像,输入到DSVDD中进行训练和预测。DSVDD中深度神经网络部分按照Conv (16, 3×3)-Leaky ReLU-ConvTran (32, 3×3)-BN-Leaky ReLU-ConvTran (64, 3×3)- BN-Leaky ReLU –FullyConnectd64的结构。训练阶段批量大小设置为128,初始学习率为0.0003,weight decay为0.0001,并训练1000次迭代。DSVDD模型是在配备Intel I7-9700K CPU,16 GB RAM和NVIDIA 2080ti GPU的计算机上使用PyTorch实现的。
-
此节将提出的DSVDD与仅使用正例样本训练的几种最新的方法取得的结果进行了比较,这些方法包括Conv-AE[15]、Stacked RNN[21]、Unmasking[23]、Davide et al.[24]、Object-centric auto-encoder[25]和MemAE[26]、New Baseline[27]。表1中列出了这些方法在两个数据集上的帧级异常检测的评估结果。
Table 1. AUC scores of the anomaly detection results
在CUHK Avenue数据集上,文中提出的DSVDD方法优于其他方法取得的结果,其AUC得分为87.4%,比2018年提出的作为基线的方法[27]高出2.3%。就目前所知,就此数据集中所有测试视频的帧级AUC得分而言,文中提出的DSVDD取得了最好的结果。值得注意的是,Object-centric auto-encoder[25]方法在他们的论文中取得了89.3%的帧级AUC,但是这个通过他们的论文中的不同指标计算得出的,通过实际计算Object-centric auto-encoder[25]方法取得的帧级AUC得分应为86.5%,比文中提出的方法低0.9%。
在ShanghaiTech Campus数据集上,文中提出的方法DSVDD实现了74.5%的帧级AUC评分,比2018年提出的作为基线的方法[27]高出1.7%,仅次于Object-centric auto-encoder[25]方法取得的78.5%。Object-centric auto-encoder[25]方法采用的是基于对象检测的方法进行异常检测,其性能在很大程度上取决于其对象检测算法的输出。因此,基于检测的方法无法确定之前未出现的异常事件,而这在异常检测中经常出现。相似地,MemAE方法[26]需要在预训练的姿势估计器的帮助才能取得较好结果,因此仅限于检测与人有关的异常事件。相比之下,文中提出的DSVDD方法没有这种局限性,并且在应用于各种场景时都非常可靠。明显地,除了这两种特殊限定的方法外,文中提出的DSVDD方法在帧级AUC上至少领先其他方法1.7%。
在图2中,展示了文中提出的方法中异常分数曲线的一些示例,并给出了一些具有正常或异常事件的关键帧。其中,横坐标为视频帧数,纵坐标异常分数已经归一化到1。可以看出,在两个数据集中,文中提出的方法可以正确区分正常和异常事件。如果突发异常事件,如图2(a)中奔跑,异常分数将急剧增加,如果异常事件是缓慢发生的,如图2(b)中缓慢走向镜头,异常分数将逐渐增加。如果导致异常的对象在摄像头视野中消失,则异常得分会迅速降低到接近0。
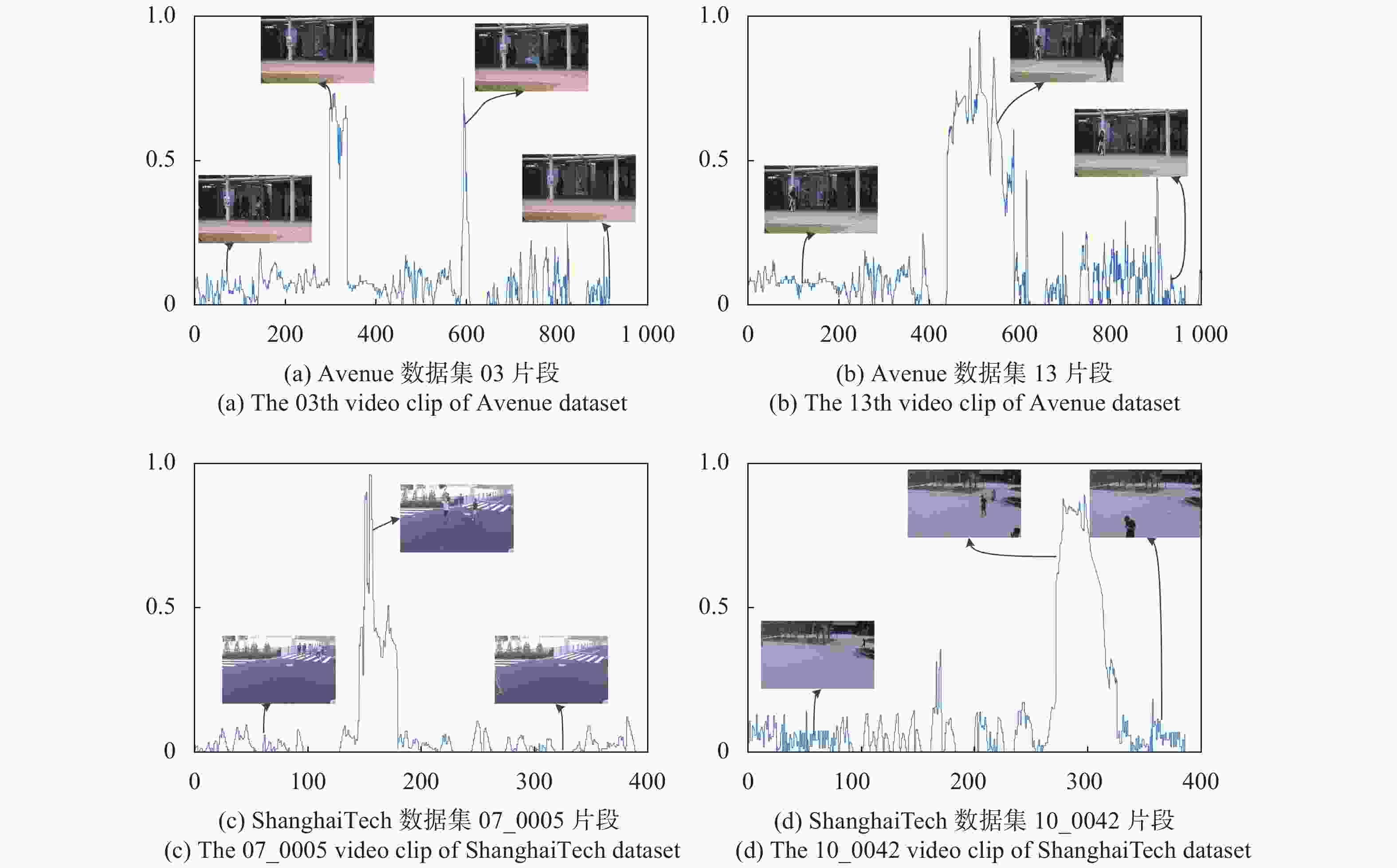
Figure 2. Examples of the detection results
2.1. 数据集
2.2. 评价指标
2.3. 补充细节
2.4. 实验结果

-
在文中提出了DSVDD,这是一种基于深度学习的视频异常检测方法。DSVDD可以看成是深度学习方法和支持向量数据描述方法的结合,采用了经过联合训练的深度神经网络,将正常样本数据映射到最小体积的超球中。那么在测试时,映射在超球面内的样本被判别为正常,而映射在超球面外的样例判别为异常。在两个公共数据集上的大量实验结果表明,文中提出的方法明显优于现有方法,这证明了文中提出的异常检测方法的有效性。今后将在保证算法准确性的基础上,降低计算复杂度,重点是提高算法的实时性能,以更好地应用于实际场景。

 DownLoad:
DownLoad: