





-
管片拼装作为盾构法隧道施工中永久衬砌结构装配的关键环节,其精度直接关系到隧道的整体质量和安全,影响隧道的防水性能及耐久性。随着隧道工程的发展,大直径盾构机使用频率不断增加,人工管片拼装操作危险、效率低和拼装质量不可控等问题随着隧道直径的增加越来越凸显[1]。因此,盾构管片自动拼装技术具有十分重要的研究价值。管片自动定位是实现自动拼装的关键。M. Wade等人报道了一种管片定位方法[2],建立了基于6自由度拼装机的管片定位数学模型,通过测量衬砌环内多点位置的方法实现管片定位。这种方法对传感系统的安装精度要求较高,且对管片初始定位的要求较高,不适用于复杂环境。Y. Tanaka 等人提出了基于光切测量技术的管片定位方法[3],该方法首先将线光源投射到已拼装管片和待拼装管片之间,然后利用视觉传感器采集图像并计算管片之间的高度差和间距。这种方法在一定程度上提高了测量精度、简化了传感系统的复杂程度,但是由于该方法主要根据管片的边缘信息判断管片位置,而管片边缘在运送过程中非常容易发生破损,影响测量精度。为了避免边缘信息缺失引起的管片定位误差,开始利用在管片表面外加特征标志的方法实现管片定位。Z. Wu等人阐述了该方法的实现流程,即通过视觉传感器采集待拼装管片内表面区域和相邻的已拼装管片内表面区域上的外加特征标志图像并计算其中心坐标,通过对比特征点的中心坐标信息确定管片的位姿信息并执行相应的定位动作,实验中所采用的特征标志是利用亚力克材料制作三角标[4]。但是,外加特征标志方法增加了作业流程,而且在固定特征标志的过程中也引入了粘贴误差,影响管片定位精度。
识别管片表面原有的特征可以避免上述问题引入的定位误差。但管片表面原本的标志动态范围小,容易受环境影响而造成轮廓特征信息丢失,需要合适的轮廓特征提取算法配合完成中心坐标计算。常见的目标轮廓特征提取算法包括基于阈值的特征提取算法[5]、基于边缘的特征提取算法[6]、基于区域的特征提取算法[7]和基于聚类[8]的特征提取算法等。但上述基于传统图像处理技术的特征提取算法难以适应复杂的盾构施工环境,在进行目标特征提取时出现性能降低甚至失效等问题。
随着基于深度学习技术的迅速发展,许多基于卷积神经网络的图像处理方法被开始被应用到轮廓特征特征提取过程,主要包括全卷积网络(FCN)[9]、金字塔场景解析网络(PSPNet)[10]和Mask R-CNN[11],其中Mask R-CNN在识别率和分割精度方面的性能最为优越。尽管上述基于卷积神经网络的轮廓特征特征提取方法优于传统的图像法,但仍然无法满足盾构管片自动拼装定位复杂环境的测量需求。
文中提出了一种基于深度学习视觉和激光辅助相结合的盾构管片自动拼装定位方法,分别利用视觉系统和激光测距系统计算待拼装管片的平面位姿和深度位姿信息,根据位姿信息计算拼装机拼装末端所需的位姿信息。为了在复杂背景下提取视觉所需的特征轮廓,提出了一种基于特殊设计的双级卷积神经网络(DSNet)的图像轮廓提取方法。搭建了盾构管片自动拼装实验平台并验证了方法的可行性。该方法系统安装简单、精度高、抗干扰能力强,具有广泛的应用前景。
-
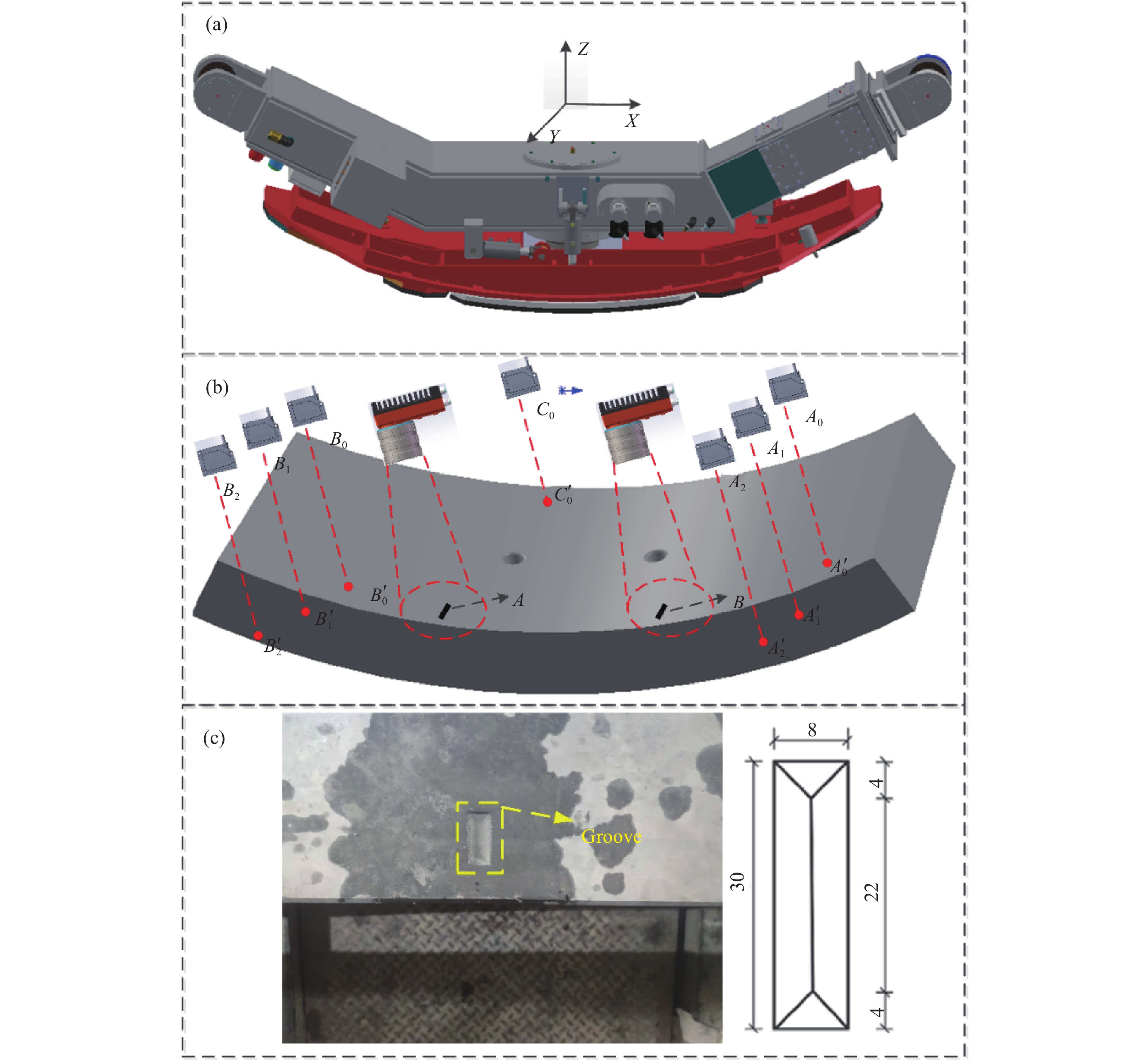
管片自动拼装定位的机械装置是一个由液压油缸和电机组成的6自由度拼装机,包括三个滑动自由度(
$x,y,{\textit{z}}$ )和3个绕轴的旋转自由度(${\theta _x},{\theta _y},{\theta _{\textit{z}}}$ )。拼装机的下表面是一个用于管片抓取的真空吸盘,如图1(a)所示。管片自动拼装定位检测的基本原理就是分别利用视觉系统和激光测距系统计算待拼装管片的平面位姿和深度位姿信息,根据位姿信息计算拼装机进行管片拼装时所需的位姿信息。其中,平面位姿的确定是依靠测量管片表面不同位置的特征点坐标实现的,而深度位姿则是利用多个激光位移传感器确定管片不同位置的高度差实现的。用于管片自动拼装定位的检测装置固定在拼装机上,其分布见图1(b),所示包括2个相机和7个激光位移传感器。自动拼装定位过程包含拼装机从地面抓取管片和将抓取的管片放置在待拼装位置两步。进行第一步操作时,保证相机可以拍摄到待拼装管片标记凹槽的位置,激光位移传感器${A_0}$ 、${B_0}$ 、${C_0}$ 的光源投射到待抓取管片上;进行第1步操作时,要保证两个相机不仅可以拍摄到待拼装管片上的凹槽,还要拍摄到已经拼装管片上对应的标记凹槽,同时激光位移传感器${A_{\rm{1}}}$ 、${A_{\rm{2}}}$ 、${B_1}$ 、${B_{\rm{2}}}$ 投射到对应的已拼装管片表面。管片上的标志凹槽照片和尺寸分别如图1(c)所示,每个凹槽都对应着一个用于管片固定的螺栓孔。因此,只要对准待拼装管片与相邻管片的凹槽,就完成了平面位姿定位。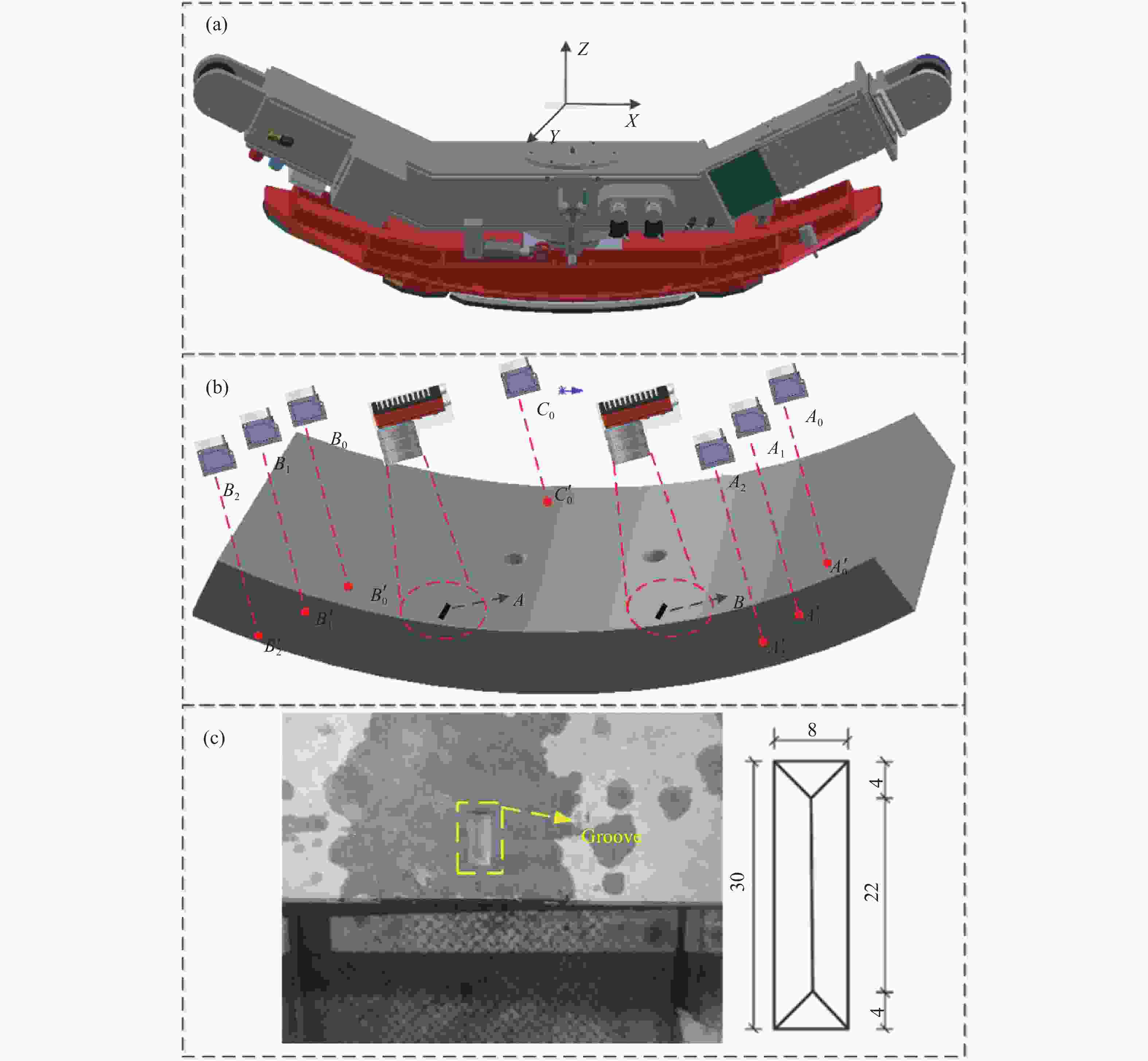
Figure 1. (a) Mechanical structure diagram of the proposed erector; (b) Layout of the detection system; (c) Physical drawing and dimension drawing of groove (Unit: mm)
平面位姿检测过程中,首先利用特征提取算法提取凹槽的轮廓信息,然后利用最小外接矩形法拟合提取的轮廓,最后计算矩形的中心坐标作为位姿检测的坐标点。凹槽轮廓信息提取是该方法的重点。管片表面图像中,背景、目标和噪声成分互不相关,包含目标凹槽的管片图像灰度值由三者线性叠加,建立如下数学模型:
式中:
$\left( {x,y} \right)$ 为空间变量,即像素点的坐标;$I\left( {x,y} \right)$ 为图像的灰度值;$T\left( {x,y} \right)$ 为目标凹槽,$B\left( {x,y} \right)$ 为背景值;$N\left( {x,y} \right)$ 图像噪声。基于此模型,管片表面凹槽的轮廓提取就是通过抑制环境污染引入的噪声和去除背景,进而获得轮廓信息的过程。由于目标和背景的对比度较低,且随机的噪声会使特征信息丢失,很难建立准确的模型拟合出背景和噪声的分布并进行相应的计算。
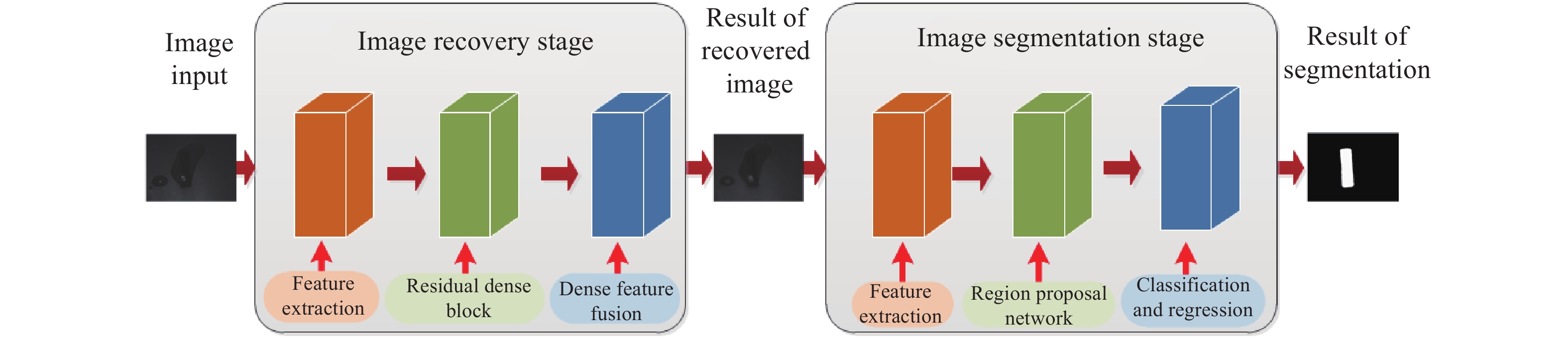
针对上述模型,文中设计的双阶段深度神经网络的管片表面特征提取框架如图2所示,根据功能划分为图像复原阶段和凹槽轮廓提取阶段。其基本工作流程为:将原始图片送入到图像复原阶段的神经网络中,进行噪声的去除,该阶段包括特征提取、残差密集块和密集特征融合3个主要部分;然后,将去除污染的图像送入到凹槽轮廓提取阶段的神经网络中,实现目标确认和目标与背景的分割,该阶段包含特征提取、候选框提取以及分类和回归3个主要部分。

Figure 2. Segment surface feature extraction framework based on two stage deep neural network
图像复原阶段的网络结构如图3所示,主要包括浅层特征提取(Shallow Feature Extraction, SFE)、残差密集块(Residual Dense Blocks, RDBs)和密集特征融合(Dense Feature Fusion,DFF)[12]。
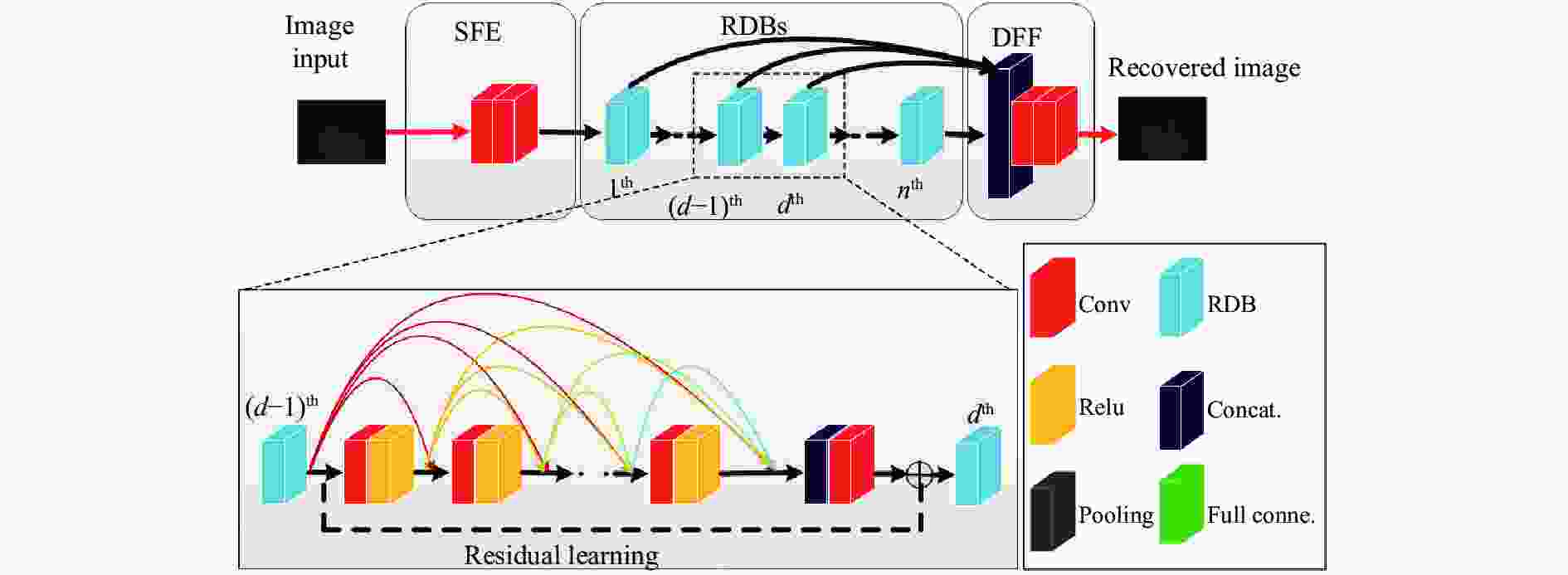
Figure 3. Schematic diagram of network framework in image restoration stage
SFE使用两个Conv层来实现。提取浅层特征的主要原因是图像复原过程中需要尽可能保留图像的细节信息,CNN的浅层特征映射表示图像的细节信息。Conv层的通道数为3,卷积核大小为3×3[13]。
RDBs由多个RDB串联组成,每一个RDB包含Conv、ReLU、特征融合和残差操作,其主要作用是处理FSE过程中输入的图像浅层特征。RDB的输出与前一项中提取到的特征有关,可以表示为[12]:
式中:
${H_{RDB - \left( d \right)}}\left( \cdot \right)$ 表示RDB的复合操作过程;${F_0}$ 指从SFE中第2层提取的浅层特征。每个RDB都有密集的连接层,这意味着RDB可以充分利用所有卷积层中的分层功能,这是整个图像增强网络通道的关键。RDB中所有的要素都通过Concat. 层,其作用就是将所有的特征图进行拼接,然后通过第3部分DFF中的1×1卷积层融合为:然后通过3×3卷积层输出级联输出
${I_{out}}$ 。图像增强通道的损耗函数定义为:式中:
$N$ 表示训练集;$I_{(i)}^{pred}\left( {x,y;\Theta } \right)$ 表示从可训练参数$\Theta $ 获悉的${i^{\rm th}}$ 图像;$I_{(i)}^{gt}\left( {x,y} \right)$ 表示相应的基本事实;${\left\| \cdot \right\|_F}$ 表示Frobenius矩阵范数。图像分割阶段的网络结构主要包括特征提取(Feature Extraction Network, FEN)、区域生成网络(Region Proposal Network, RPN)和分类和回归网络(Classification and Regression Network,CRN)[14]。
-
双阶段深度神经网络的模型训练采用监督学习方式分别训练。第1阶段训练中,利用分辨率为1280×1024 pixel的摄像机拍摄表面被污染的管片照片,再拍摄相同位置干净的管片照片作为训练标签,共包含140组图像对。在第2阶段训练中利用同样的摄像机拍摄不同高度、不同角度、不同曝光时间以及不同污染程度的包含凹槽的管片表面照片1200张。根据不同阶段所要实现的不同功能,分别用峰值信噪比(Peak Signal to Noise Ratio,PSNR)和掩膜损失函数(
${L_{mask}}$ )来评价两个阶段的训练效果。图4(a)是第1阶段的峰值信噪比曲线,通过曲线可知当进行15000代训练(Epoch)后,训练的PSNR曲线趋于稳定,表明进行复原的图像失真达到最小值,可以结束训练。图4(b)是第2阶段的掩膜损失函数曲线,可以发现进行1000 Epoch后损失函数值接近0。
Figure 4. (a) PSNR curve of the first stage; (b) Mask loss function curve of the second stage
为了验证特征提取算法效果,在保持相机和管片位置不变且管片表面干净的条件下连续采集了10张含有凹槽的管片表面图片,分别利用文中提出的特征提取算法和传统Mask R-CNN算法进行凹槽轮廓中心计算,结果表明两种方法得到的凹槽轮廓中心坐标的最大差值的横坐标分别为1和2个像素单位,纵坐标均为3个像素单位,每个像素单位对应着0.1 mm的水平距离,面积的最大差值在3%以内。为了量化算法的效果,使用这10次的测量结果的平均值作为标准坐标和标准面积,使用坐标误差的绝对值(CE)和误差面积比的绝对值(EAR)用于评估所提出的双阶段深度神经网络特征提取算法的有效性。
图5对比了文中提出的特征提取算法和传统Mask R-CNN算法在管片表明污染情况下的轮廓特征提取效果。图中的绿色轮廓线和红色轮廓线分别为轮廓特征提取结果和标准结果。图5(a)和(b)是基于传统Mask R-CNN算法的结果,图5(c)和(d)是对应文中提出的特征提取算法的结果。

Figure 5. Comparison of different contour feature extraction methods. (a) and (b) Processing results based on the traditional Mask R-CNN algorithm; (c) and (d) Processing results based on proposed algorithm in the paper; (e) and (f) Processing results of original image based on proposed algorithm in the paper
可以看出,文中所提方法的方法在CE和EAR方面都优于传统Mask R-CNN算法的特征提取结果。这是因为水污染管片表面凹槽之后,凹槽轮廓的部分信息丢失,虽然Mask R-CNN可以根据较深层的特征信息提取凹槽的轮廓特征,但由于浅层的细节信息丢失,使得凹槽的轮廓特征不精确。而双阶段深度神经网络法在进行凹槽轮廓特征提取之前,在第1阶段进行了图像增强,降低了污染对凹槽轮廓信息提取的影响,再通过第2阶段的特征提取,实现了较为精确的凹槽轮廓特征提取。当污染严重时,Mask R-CNN的轮廓提取方法是无效的,但是文中所提的方法仍然可以工作,并且可以获得良好的结果,见图5(e)和(f)。
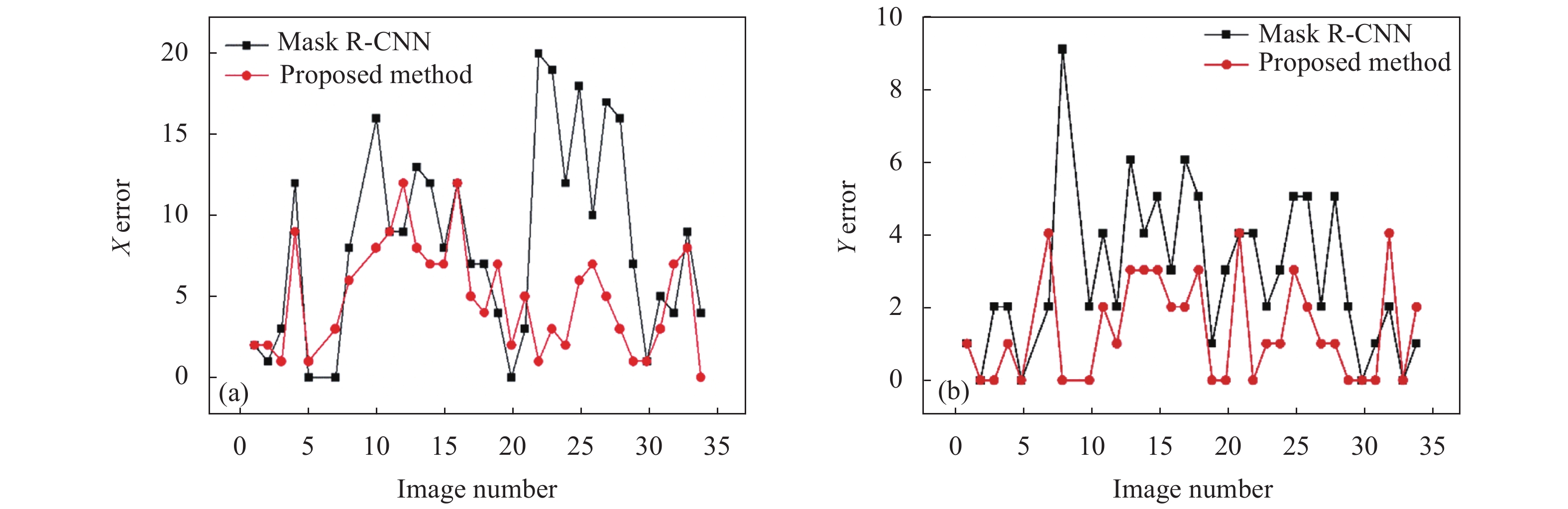
图6(a)和6(b)分别对比了基于传统Mask R-CNN算法、文中所提算法的处理结果在X和Y方向上的CE值分布,可以看出基于文中所提算法的处理结果比基于传统Mask R-CNN算法的结果的CE值小,对应的特征提取精度高。此外,文中说使用方法的识别率为86.7%,高于Mask R-CNN的58.3%。
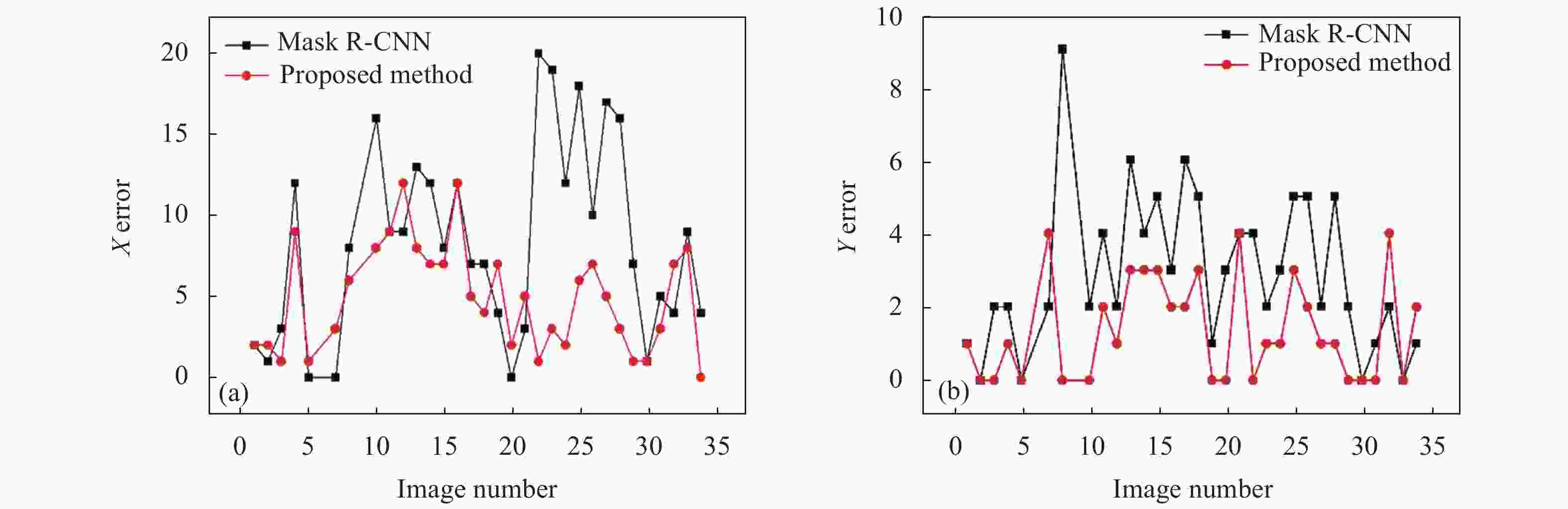
Figure 6. (a) CE value in X direction; (b) CE value in Y direction
-
智能相机和激光位移传感器在拼装过程中不发生机械干涉的情况下,通过金属支架安装在拼装机边缘。相机和传感器的光轴在拼装机和管片吸合的情况下垂直于管片表面,相机的像素中心点与标志凹槽的中心重合。图7展示了相机和激光位移传感器的现场安装图。

Figure 7. Experimental diagram of segment automatic assembly positioning
为了验证定位精度,实验进行前,在液压油缸和电机上分别安装了行程传感器和编码器,记录定位完成时行程传感器和编码器的数值作为标准数值。进行实验时,利用文中提出的定位方法完成定位后,用当前的行程传感器和编码器的数值和标准数值进行对比,取误差最大的一组作为定位精度值。
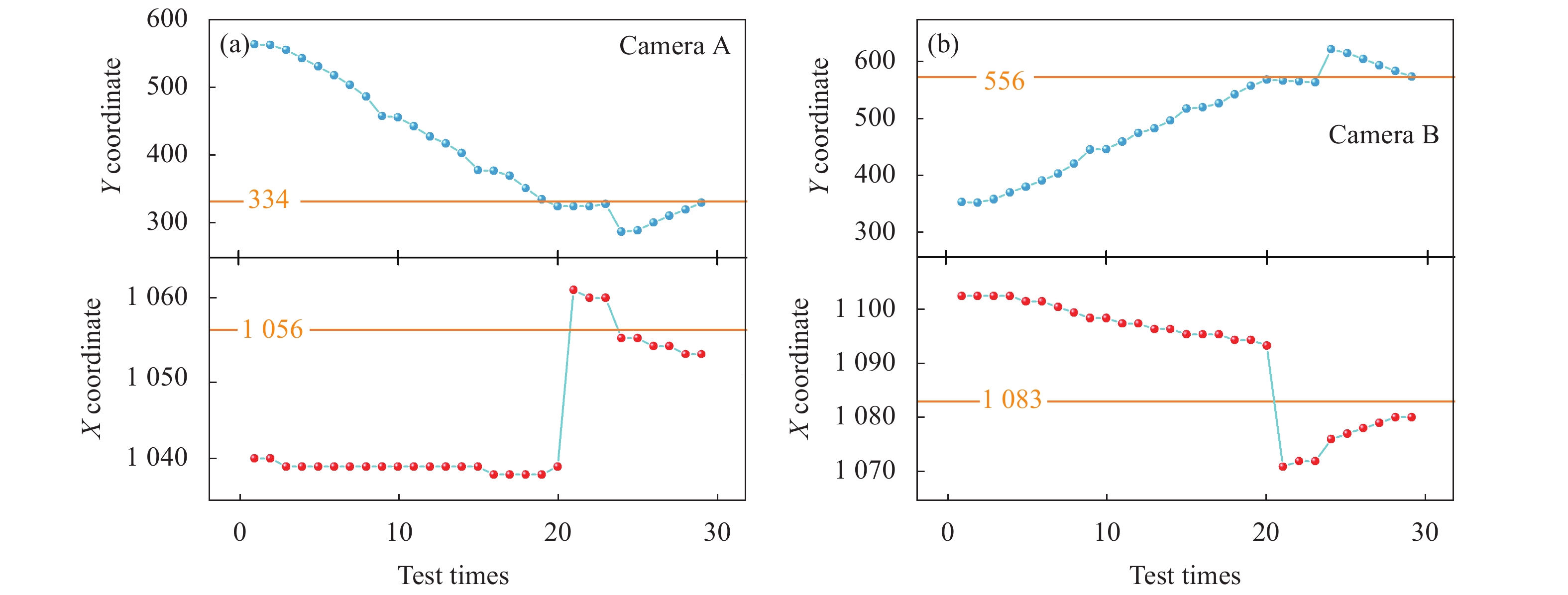
首先进行了管片的抓取实验。图8(a)和(b)分别是相机定位过程中两个相机检测到的标志坐标随拼装机位姿调整的变化曲线,图像中的黄线是相机定位的标定值。相机进行位姿调节的顺序是横摇、旋转和滑动。从图中可以发现,随着位姿的调整,相机得到的坐标值不断接近标定值。实验中相机定位完成后最大的定位误差为4个像素点,对应的定位误差约0.4 mm。
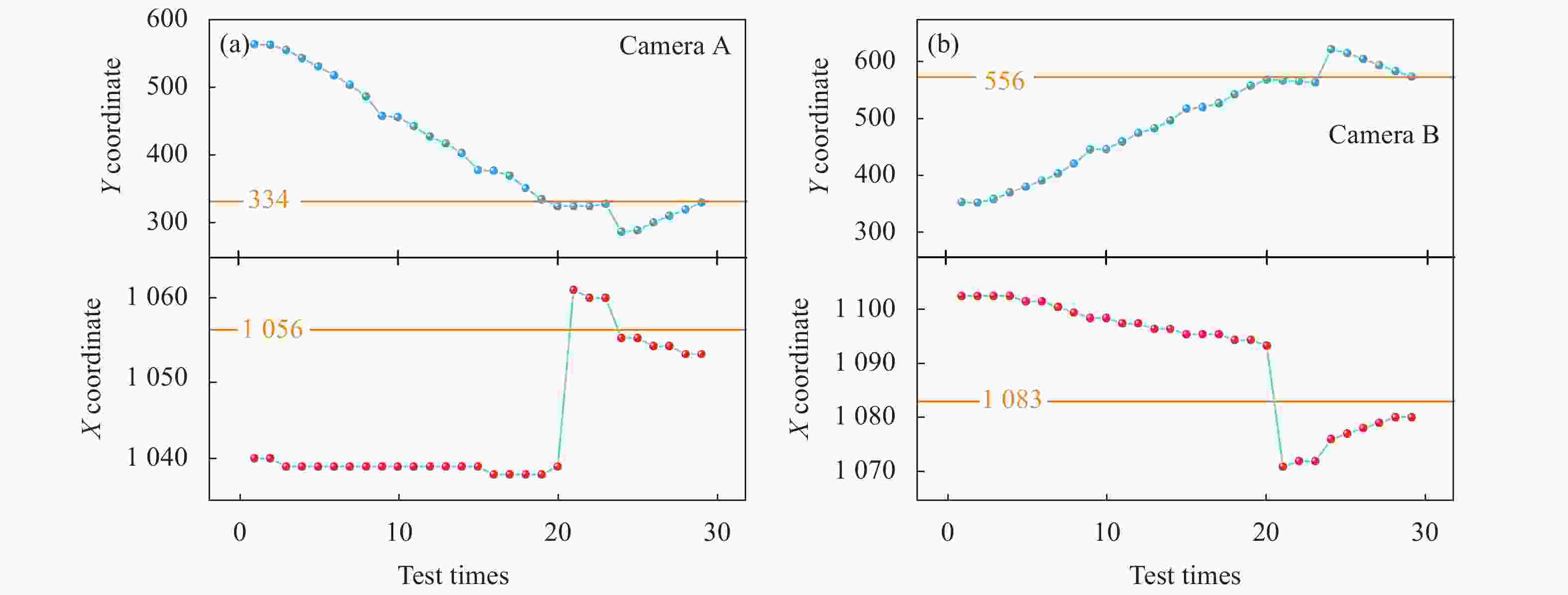
Figure 8. Change curves of the mark coordinates detected by two cameras with the pose adjustment of the assembly machine during the process of camera grabbing and positioning
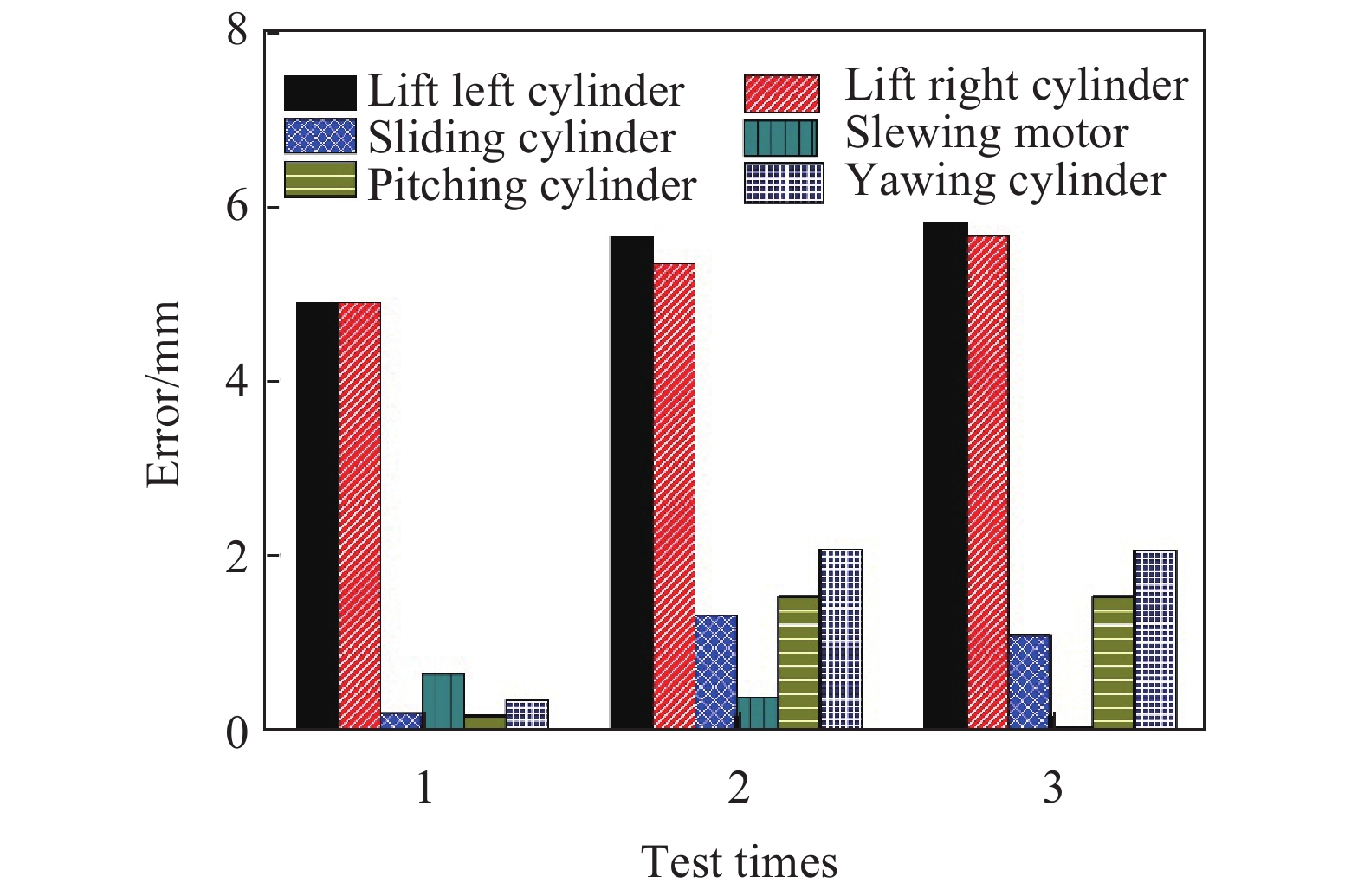
图9是3次测量盾构管片自动抓取实验的执行机构最终定位误差的绝对值。实验结果表明:测试中提升油缸的误差较大,最大误差为5.78 mm,其余油缸的定位误差均小于3 mm。提升油缸误差较大的原因是为了避免拼装机下降过程中因拼装机下压严重造成管片或喂片机损坏,在拼装机下降到标定位置之前停止下降,只要吸盘下表面的胶圈与管片上表面接触就可以隔绝外界空气,实现真空抓取。
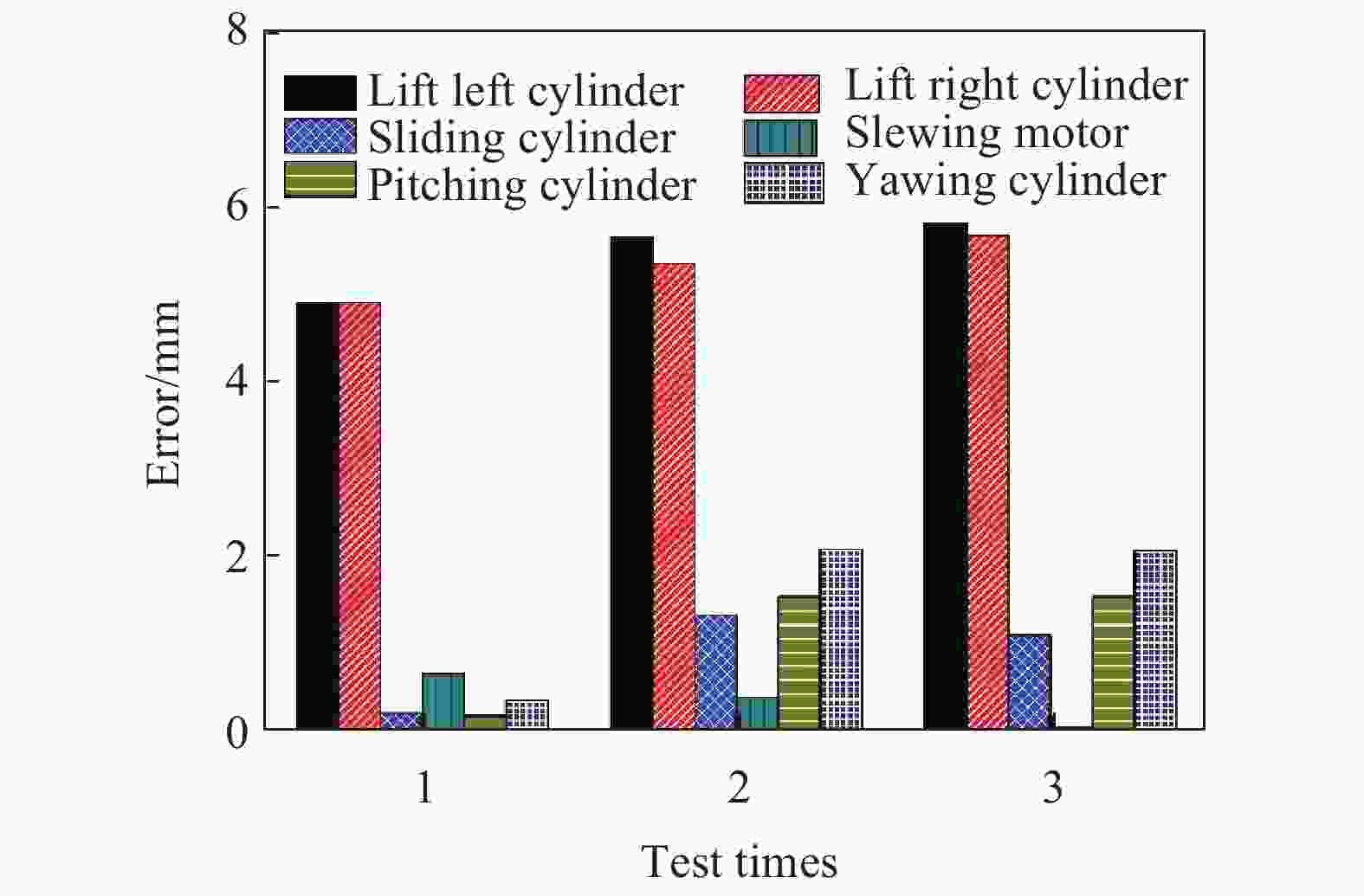
Figure 9. Absolute value of grab positioning error
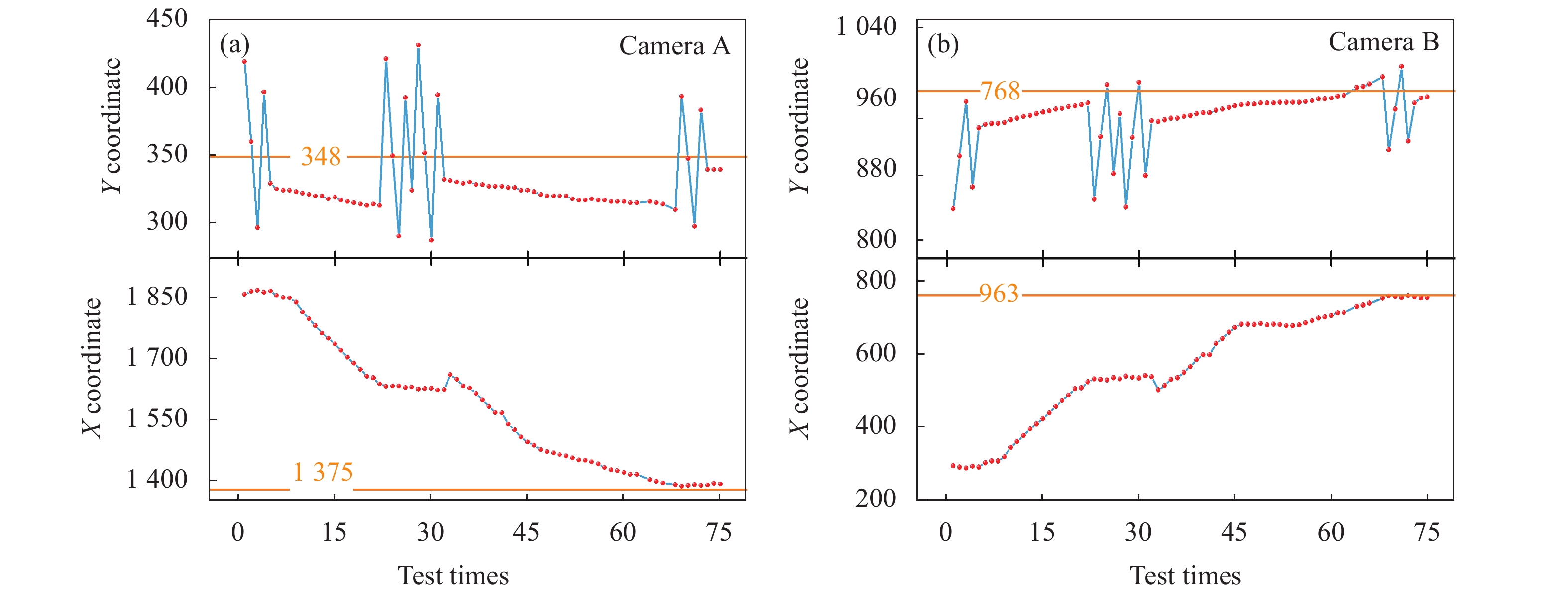
图10(a)和(b) 分别是相机拼装定位过程中两个相机检测到的标志坐标随拼装机位姿调整的变化曲线,图像中的黄线是相机定位的标定值。相机进行位姿调节的顺序是横摇、旋转和滑动。从图中可以发现,随着位姿的调整,相机得到的坐标值不断接近标定值。实验中还发现坐标的Y值在某些调整位置中会反复发生大范围的波动,这是因为当调整旋转电机动作时,由于重力作用,使得拼装机无法固定在目标定位位置,需要相机在旋转自由度上进行反复调节直到满足拼装误差要求。实验中相机定位完成后最大的定位误差为2个像素点,对应的定位误差约0.2 mm。

Figure 10. Change curves of mark coordinates detected by two cameras with pose adjustment of assembly machine during camera positioning
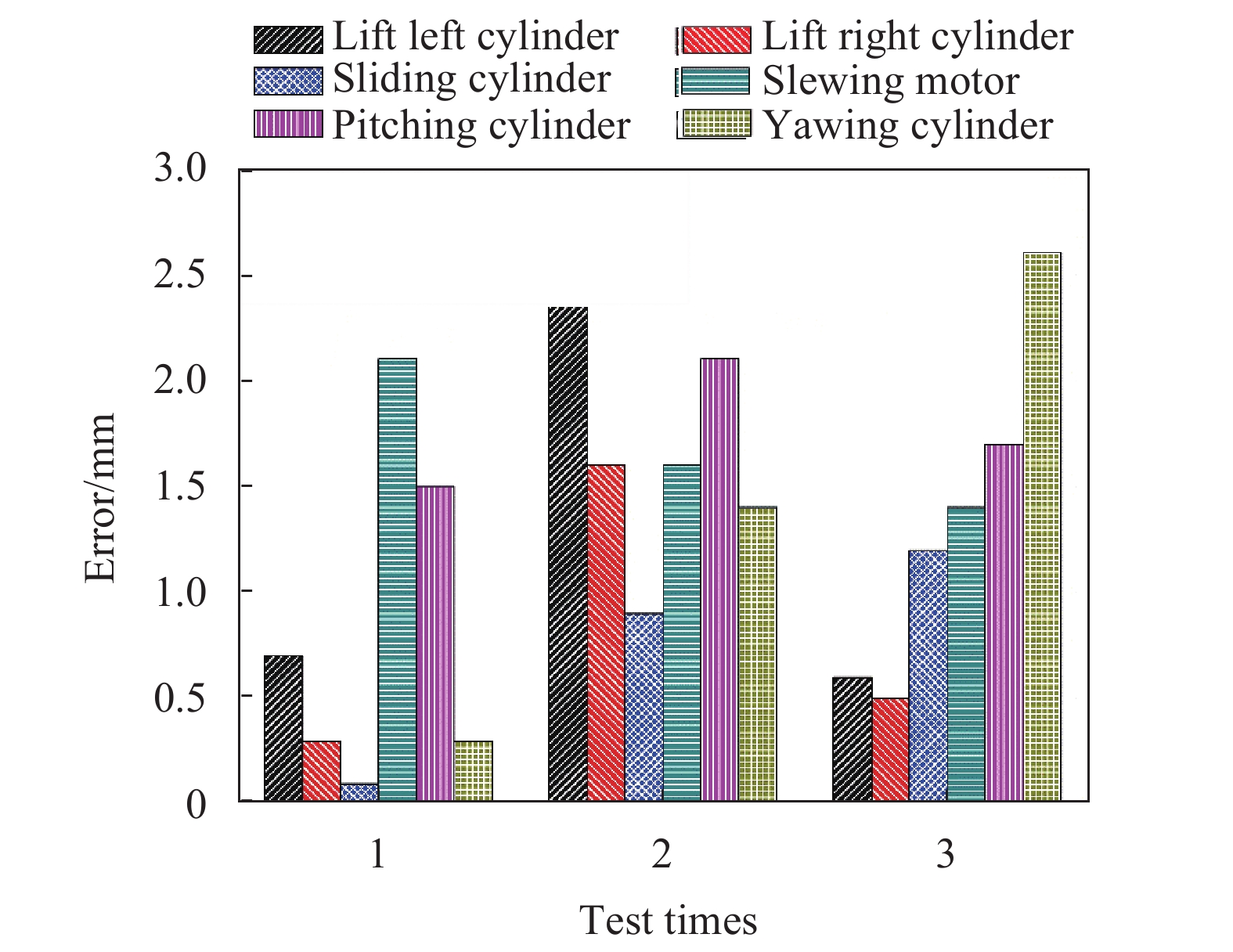
图11是3次测量盾构管片自动抓取实验的执行机构最终定位误差的绝对值。实验结果表明:测试中油缸的定位误差均小于3 mm,满足盾构管片自动拼装定位的精度要求。
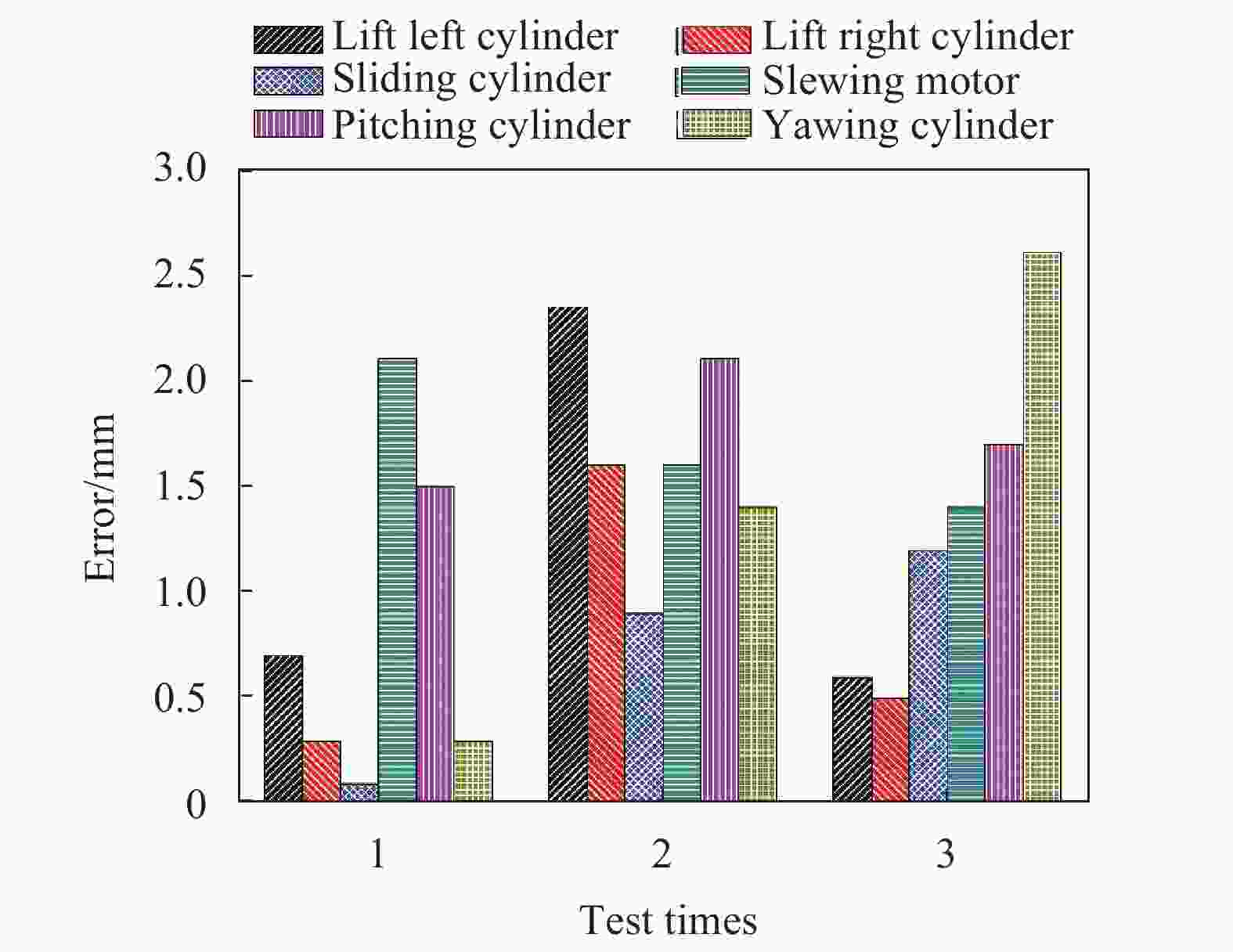
Figure 11. Absolute value of assembly positioning error
-
文中提出了一种基于深度学习视觉和激光辅助相结合的盾构管片自动拼装定位方法,利用视觉系统和激光测距系统计算待拼装管片的平面位姿和深度位姿信息。提出的双阶段卷积神经网络可以实现管片表面定位标志轮廓特征的有效提取,实验表明:文中提出的双阶段卷积神经网络算法相比于现有的特征提取算法,在管片表面污染的情况下提取精度不仅明显提高,识别率也提升了28.4%。管片自动拼装定位实验表明:所提出的盾构管片自动拼装定位方法的定位精度小于3 mm,高于人工10 mm的定位精度,能够有效地用于盾构管片自动拼装定位。
Automatic assembly positioning method of shield tunnel segments based on deep learning vision and laser assistance
doi: 10.3788/IRLA20210183
- Received Date: 2021-03-17
- Rev Recd Date: 2021-03-25
- Publish Date: 2022-05-06
Fund Project:
National Key Research and Development Program of China(2018YFF01013200)
-
Key words:
- deep learning /
- segment location /
- feature extraction
Abstract: The positioning of tunnel segments is the key to realize the automatic assembly of shield segments. This paper proposed a method for automatic assembly and positioning of shield segments based on the combination of deep learning vision and laser assistance. The plane pose and depth pose information of the segments to be assembled were obtained by vision system and laser ranging system, respectively. The vision system based on the specially designed two-stage convolutional neural network could effectively extract the contour features of the segment surface positioning marks, and the extraction accuracy and recognition rate were significantly improved compared with existing algorithms. Experiments show that the proposed automatic assembly positioning method of shield segment can meet the requirements of automatic assembly and positioning of shield segment.





























 DownLoad:
DownLoad: