





-
近年来,3D模型成像技术发展非常迅速,数据获取更加便捷。点云是3D模型数据中一种重要的表现形式,包含着大量的空间几何信息,使模型的描述更加直观和准确。3D点云处理技术已广泛应用于智能车辆、模型重构、医学成像和遥感测绘等领域,成为计算机视觉和图形学领域的重要研究项目。因此,对3D点云数据处理显得至关重要。
传统点云处理方法主要通过手工设计几何形状[1]描述符或签名描述符[2]对特征进行提取。手工设计的描述符效果较差,导致提取到的特征数量变少,进而影响最终的实验结果。近年来,深度学习3D点云算法[3-4]以处理数据量大等优势受到学者们的广泛关注。由于点云数据的稀疏性、非结构性和无序性,传统的卷积神经网络不适合直接应用于点云领域。针对此问题,Qi等人[5]提出PointNet网络,通过多层感知器直接学习点的特征,并结合基于对称函数思想的最大池化方法处理点云数据的无序性难题。该算法较好地解决了卷积神经网络直接应用的问题,但点云特征得不到完整地提取。为此,Qi等人[6]针对PointNet的不足之处进行了修改,设计出PointNet++,首次提出基于最远点采样的局部特征提取。相较于PointNet有显著提升,但是仍缺乏点与点之间相互关系的表示。Li等人[7]提出点卷积网络(Point Convolutional Neural Networks,PointCNN)以解决点云的无序排列问题,该网络没有采用最大池化作为对称函数,而是训练了一个“X”型的变换网络,但是局部几何信息仍有大量的丢失。Wang等人[8]提出动态图卷积神经网络(Dynamic Graph Convolutional Neural Networks, DGCNN),通过最近K阶邻点采样(K Nearest Neighbor, KNN)获取局部信息,构造局部图结构并提取该部分特征,效果比PointCNN[7]更好,且未造成有效信息的丢失。尽管DGCNN[8]能够很好地采集低级语义信息,仍无法描述大部分的高级语义信息和隐式高级语义特征。
针对上述研究方法的不足,文中提出一种局部语义信息补偿全局特征的点云学习网络,通过扩张卷积来增大特征提取的范围,在保持点云序列不变的情况下,利用边缘卷积提取几何特征。目的是尽可能考虑点的坐标与邻点的距离,避免部分几何信息提取不完整的问题。在局部特征提取时,利用KNN模块来提取低级语义信息,并利用局部特征融合(Vector of Locally Aggregated Descriptors,VLAD)模块将所提取到的低级语义信息来描述高级语义信息和隐式高级语义特征,进一步补偿全局提取时遗漏的特征及有效信息。实验及分析表明,文中网络对点云的全局及局部特征提取效果具有显著的提高,低级语义信息描述高级语义特征也得到了进一步的完善。
-
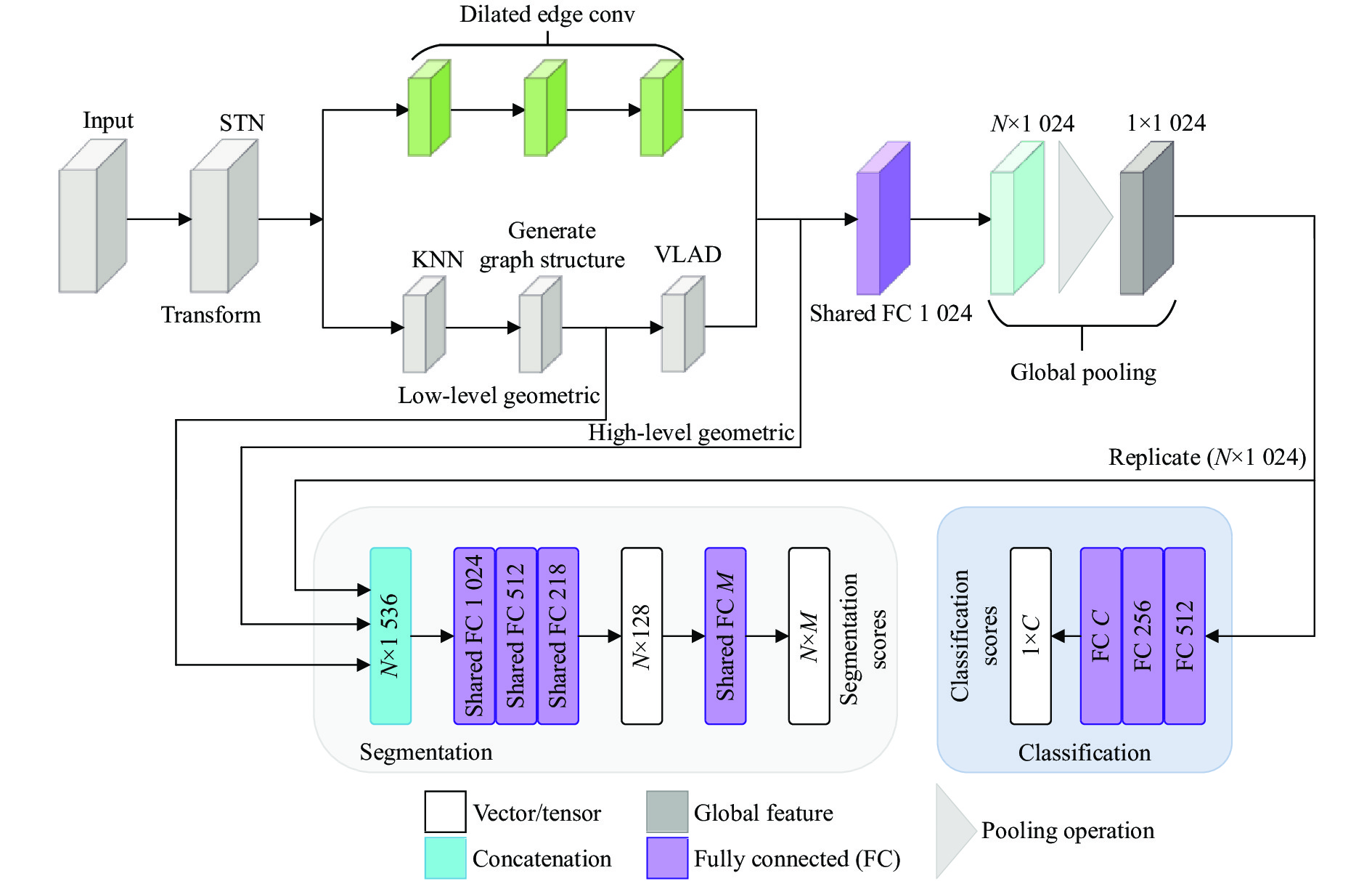
图1为网络的总体架构,由点云特征提取学习、分类处理和分割处理三部分组成。其中点云特征提取学习为核心部分,首先将所输入的点云数据通过规范空间(Spatial Transformer Network,STN)模块进行输入转换处理;其次利用扩张边缘卷积(Dilated-Edge conv)模块提取各层点云特征,并汇总成全局特征;最后利用KNN-VLAD模块提取点云局部特征,与全局特征进行融合生成更完整的点云特征。

Figure 1. Schematic diagram of network structure and process
-
3D点云数据是由一组排列无序的3D点
$ P = \left\{ {{p_1},{p_2},\cdots,{p_N}|{p_n} \in {{\boldsymbol{R}}^3}} \right\} $ 组成,其中各点坐标为$ \left( {x,y,{\textit{z}}} \right) $ ,将这组点进行空间转换处理,定义如下:式中:
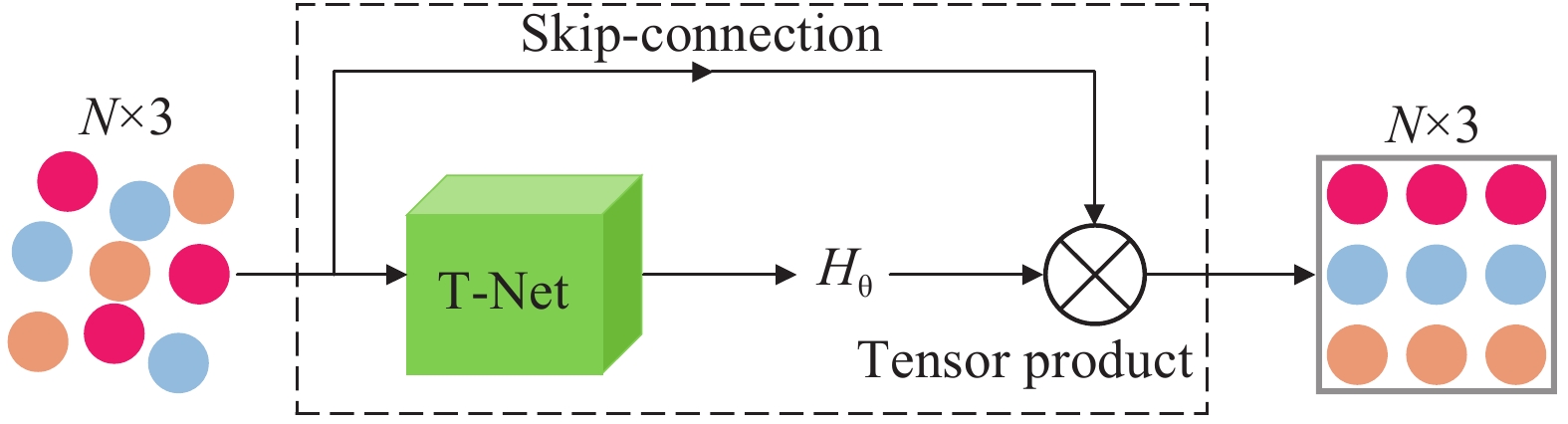
$ \mathop P\limits^ \sim $ 为空间中转换后的3D点云数据;$ {{\boldsymbol{H}}_{\boldsymbol{\theta }}} $ 为转换后的矩阵.$ {{\boldsymbol{H}}_{\boldsymbol{\theta }}} $ 可以表示为:Jaderberg等人[9]提出利用深度学习对齐2D图像的空间转换,文中对此进行创新改进并运用至3D点云数据上,通过STN模块对点云数据进行输入转换处理。该模块通过端到端的方式将输入点云进行空间规范,保证其输入后依然保持空间序列的不变性。图2为经STN模块输入转换后的矩阵。

Figure 2. Diagram of STN input conversion structure
图2中,T-Net表示一个回归网络,将输入的点云数据转化为含有9个参数的矩阵
$ {H_\theta } $ 输出。STN模块将输入的点云数据编排至一个规范的矩阵,不改变点云数据排列方式并传到下一模块进行处理,通过规范空间的排列解决了点云数据的无序性。 -
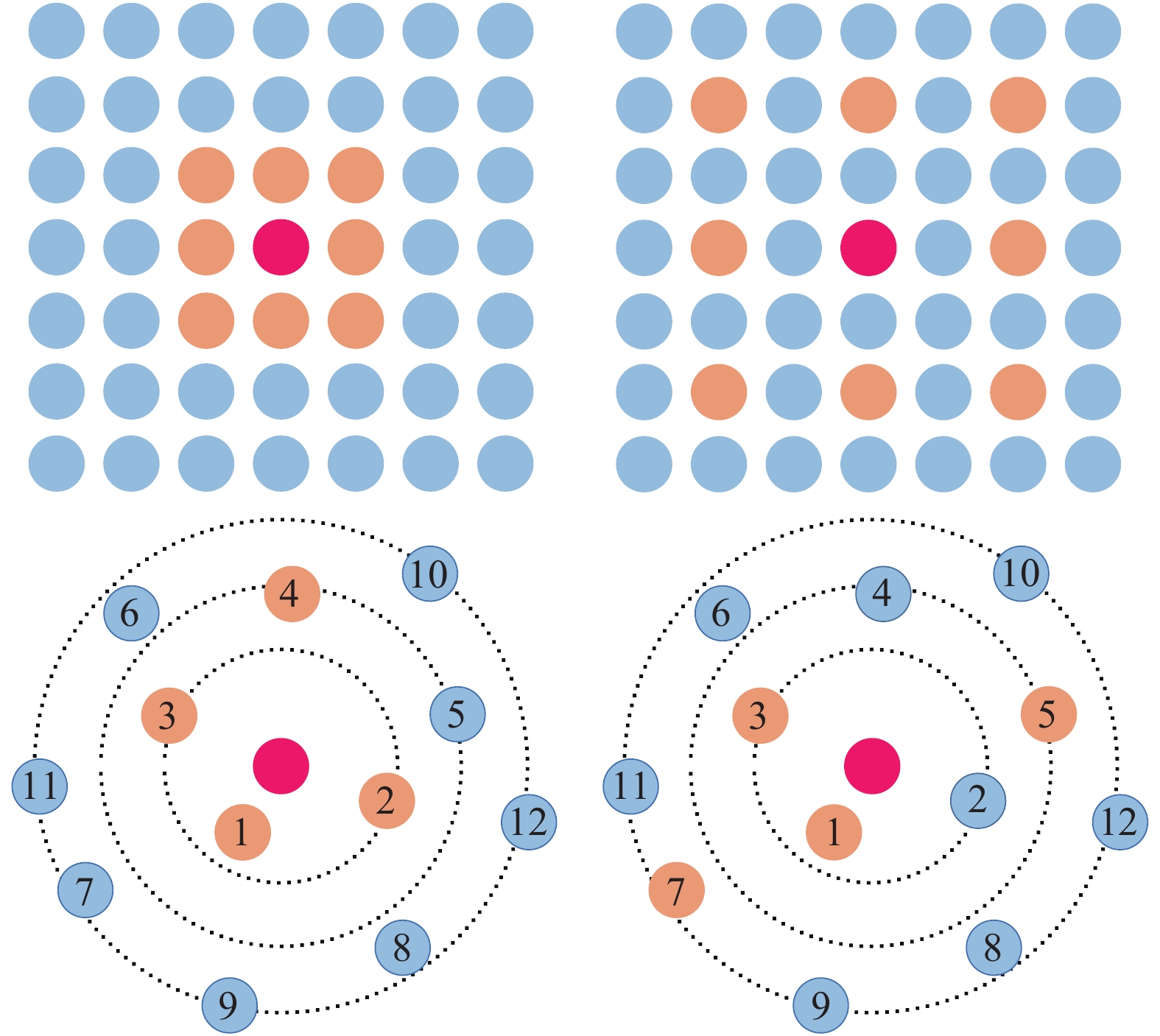
KNN(K Nearest Neighbor)[10]表示:该算法通过采用测量不同特征值之间的距离方法进行分类。其优点在于精度高,对于异常值不敏感以及无需数据输入假定。
经STN模块转换后,原始3D点集
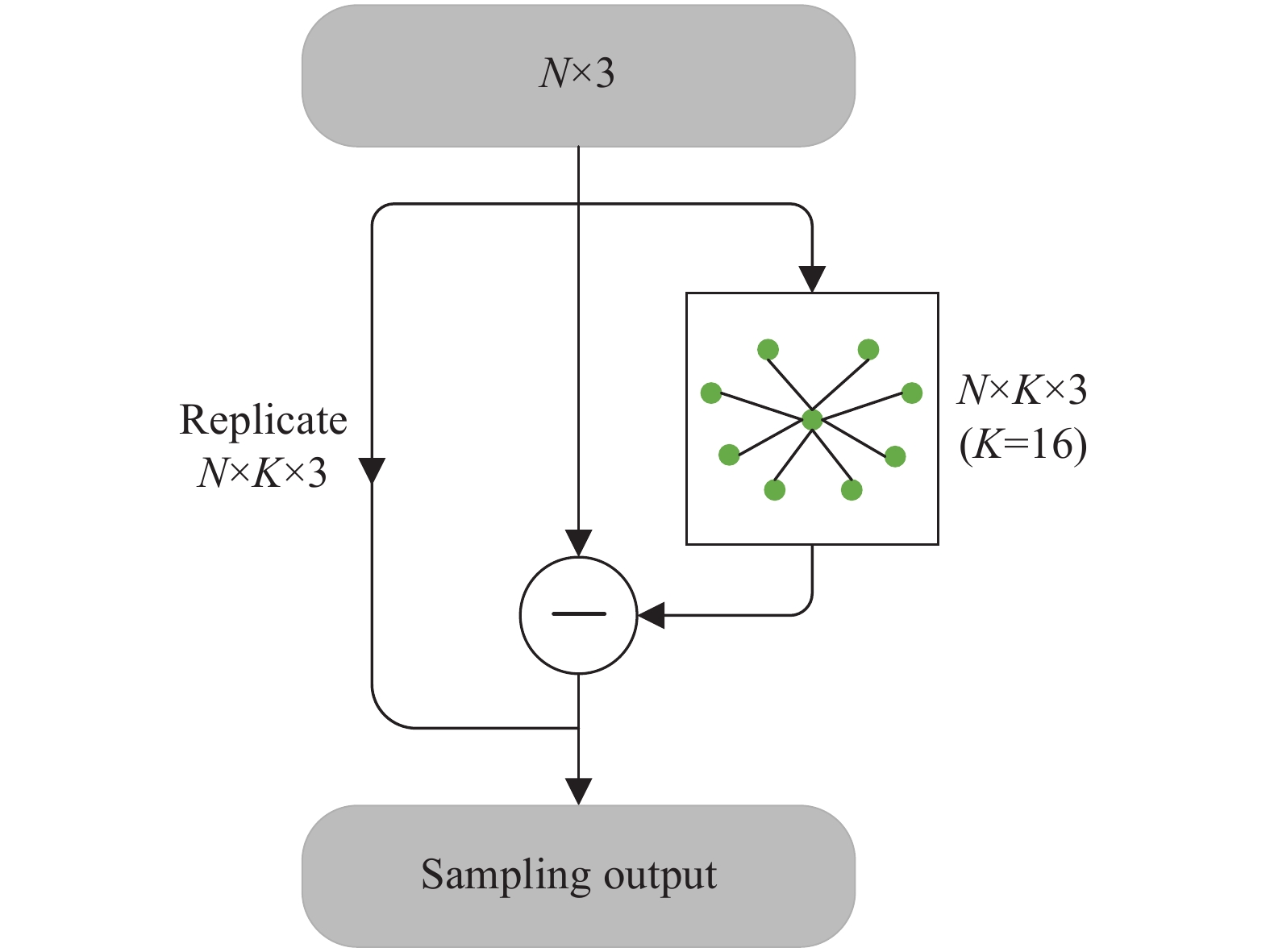
$ P = \{ {{p_1},} {{p_2},\cdots,{p_N}|{p_n} \in {{\boldsymbol{R}}^3}} \} $ 转换为规范空间的3D点集$ \mathop P\limits^ \sim = \left\{ {\mathop {{p_1}}\limits^ \sim ,\mathop {{p_2}}\limits^ \sim ,\mathop {\cdots,{p_N}}\limits^ \sim |\mathop {{p_n}}\limits^ \sim \in {{\boldsymbol{R}}^3}} \right\} $ 。将规范好的3D点集输入到KNN模块,提取低级几何特征,KNN模块结构如图3所示。图中,在3D点集$\mathop P\limits^ \sim - {{\mathop p\limits^ \sim } _n}$ 中的每个点采集$ K(K = 16) $ 阶最近邻点。$ k $ 阶采集可表示为:
Figure 3. The structure of KNN module
式中:
$ k \in K $ 且$ k \leqslant K{\text{ = }}16 $ ;${{\mathop p\limits^ \wedge} _{n,k}}$ 表示点${{\mathop p\limits^ \sim} _n}$ 的第$ k $ 个最近邻点。因此,${{\mathop p\limits^ \sim } _n}$ 的$ K $ 个最近邻集可以表示为:在该网络中KNN模块有两个作用:(1) VLAD模块利用KNN所采集到的低级语义信息来描述高级语义信息和隐式高级语义特征。(2) 扩张边缘卷积模块利用KNN采集得到的点集,并提取点的有效信息来构造全局特征图。
-
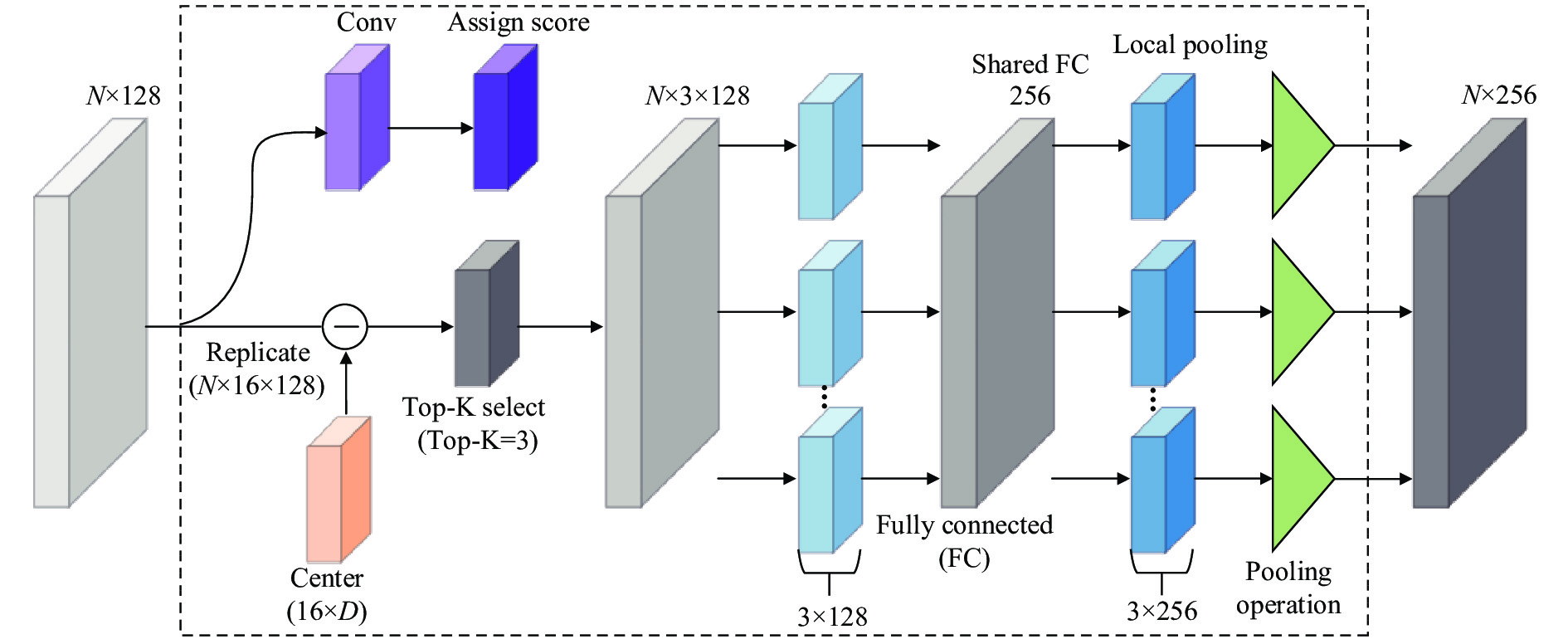
VLAD[11]是一种经典的实例检索和图像分类的描述符池化方法。直接描述点云高级语义特征的隐式表达式是极为困难的,为解决这一问题文中利用KNN所提取到的低级语义信息描述符与一些视觉词之间的关系,来间接描述高级语义特征。VLAD结构如图4所示,改进的VLAD模块主要有两个功能:(1) Top-K特征的选择;(2) 特征的变化与融合。

Figure 4. VLAD structure diagram
Top-K 特征选择:选择
$ N $ 个低级语义信息描述符$ \left\{ {{v_1},\cdots,{v_N}|{v_n} \in {{\boldsymbol{R}}^D}} \right\} $ (其中$ D = 128 $ )作为VLAD的输入,$ M $ 个视觉词(视觉词可以为“集群中心”)初始化,表示为$ \left\{ {{c_1},\cdots,{c_M}|{c_m} \in {{\boldsymbol{R}}^D}} \right\} $ ,将可学习的参数反向传播。把各点的低级语义信息描述符$ {v_n} $ 分配给各个$ {c_m} $ ,可以使用残差向量$ ({v_m} - {c_m}) $ 表示,并记录二者之间的差异。点的低级语义信息描述符$ {v_n} $ 与视觉词之间的关系$ r $ 可以表示为:式中:
$ {a_n}({c_m}) $ 是注意系数;$ {c_{m,d}} $ 和$ {v_{n,d}} $ 分别是$ d $ 维中的第$ m $ 视觉词和第$ n $ 个点的低级语义信息描述符。权重可以利用注意系数$ {a_n}({c_m}) $ 表示,突出第$ m $ 个视觉词和第$ n $ 个点的低级语义信息描述符的重要性。$ {c_m} $ 和$ {v_n} $ 的距离最近时$ {a_n}({c_m}) = 1 $ ,反之则为0。文中对视觉词和低级语义信息描述符进行softmax处理,目的是让VLAD模块的注意系数更容易在不同视觉词之间比较,注意系数的计算表达式为:
式中:
$ {w_m} $ 表示权重;$ {b_m} $ 表示偏差;$ {a_n}({c_m}) $ 将最高权重分配给距离最近的视觉词,取值范围为$ [0,1] $ 。公式(5)是每个视觉词的残差加权和,由于3D模型组各点可能与多个视觉词相关联,需要分析较高注意系数的视觉词对高级语义特征的影响。则公式(6)应设定一个低级语义信息描述符$ {v_n} $ 和一个视觉词集合$C = \{ {c_1},\cdots, {c_M}|{c_m} \in {{\boldsymbol{R}}^D}\}$ ,Top-K的注意力数值返回一个子集$ \mathop C\limits^{\sim} = \{ \mathop {{c_1}}\limits^{\sim} ,\cdots,\mathop {{c_K}}\limits^{\sim} |\mathop {{c_k}}\limits^{\sim} \in {{\boldsymbol{R}}^D}\} $ ,$ \mathop C\limits^{\sim} \in C $ ,使得任意一个视觉词都有$ \mathop c\limits^{\sim} \in \mathop C\limits^{\sim} $ 并且$ \mathop c\limits^{\sim}{ sim}in C - \mathop C\limits^{\sim} ,{a_n}(\mathop c\limits^{\sim} ) \geqslant {a_n}(\mathop c\limits^ \wedge ) $ 。将公式(6)改进可得:式中:
$ k \in [1,top - K],d \in [1,D] $ 。Top-K既可以控制剩余向量的数量,又可以表示不同视觉词之间的重叠。引入共享FC层以便改善网络的非线性变化,最后融合Top-K变换后的特征。图4中,在网络初始化过程中,通过
$ [ - 0.01,0.01] $ 的统一初始化得到视觉单词。然后,在网络训练过程中,通过优化损失函数对其进行不断调整。将视觉词$ {c_m} $ softmax(软分配)给低级几何特征描述符$ {v_n} $ 可以视为一个两步过程:(1) 与一组$ M $ 个滤波器$ \{ {w_m}\} $ 卷积,具有空间支持$ 1 \times 1 $ 和偏差$ \{ {b_m}\} $ ,产生输出$w_m^{\rm{T}}{v_n} + {b_m}$ 。(2) 卷积输出通过softmax传输函数获得最终的软分配$ {a_n}({c_m}) $ 。Top-K的特征将根据该定义来执行选择。文中将KNN和VLAD模块进行融合,KNN模块负责提取点云数据中的低级语义信息,VLAD模块将KNN提取到的信息进行整合并描述点云特征中难以提取到的高级语义信息和隐式高级语义特征。两个模块相辅相成,共同描述全局特征中遗漏的有效信息,为整体特征完整性的表示起到了决定性的作用。
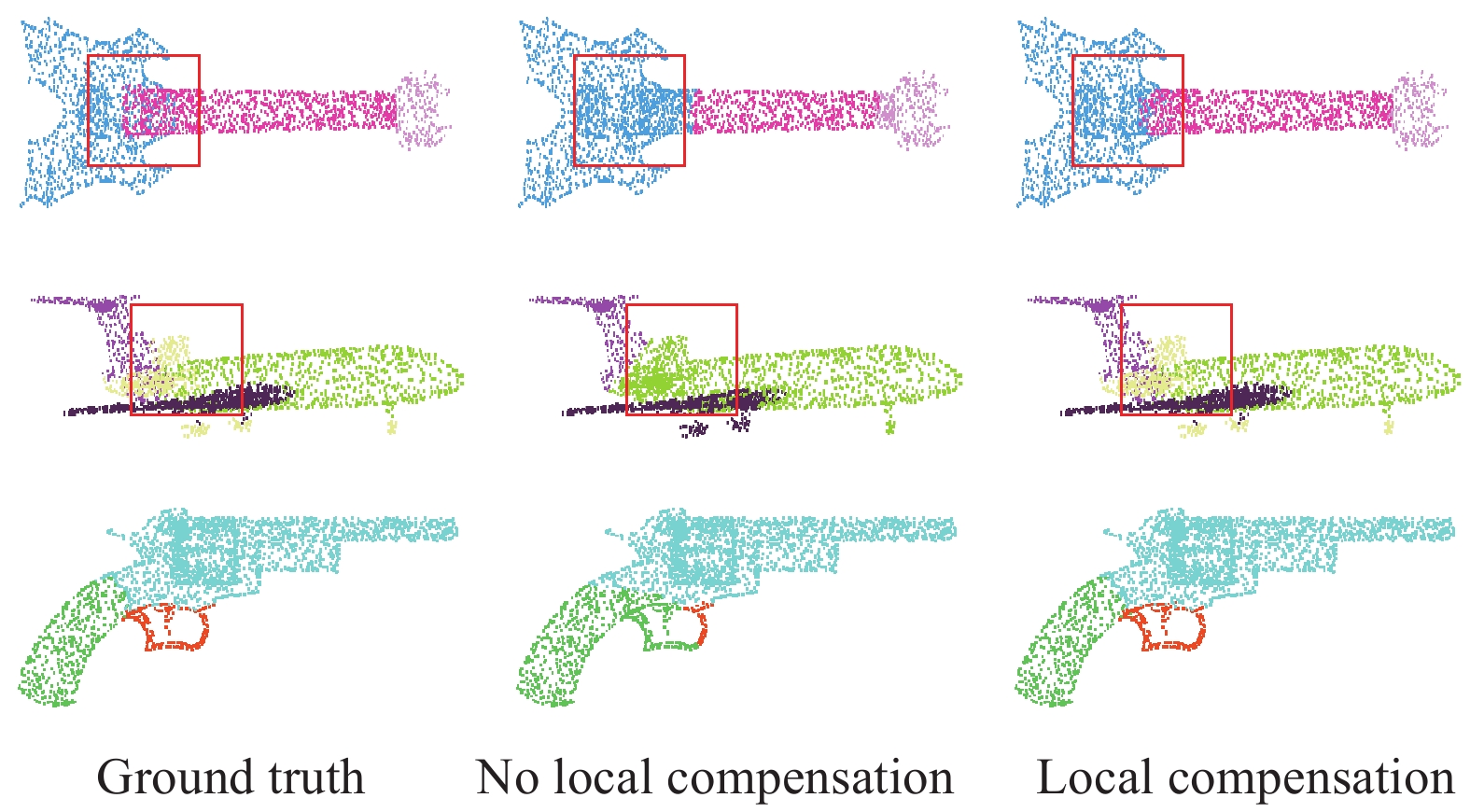
如图5所示,第一列为真实物体分割结果,第二列为无局部补偿全局特征的分割结果,第三列是含有局部补偿全局特征的分割结果,依据图中红色方框标记处可知。当不含有局部补偿全局特征时,虽然能够大致分割标记出物体各部分组织的形状,但是由于缺少局部高级语义信息和一些隐式高级语义特征地补偿,导致物体的一些细微地方出现分割标记错误的情况。例如,吉他的琴弦处、飞机的尾翼处以及手枪的扳机处。由此可见,局部高级语义信息以及隐式高级语义特征补偿全局特征能够更好地表示物体各部分特征的细节,充实整体特征的表示。

Figure 5. Comparison of partial compensation
-
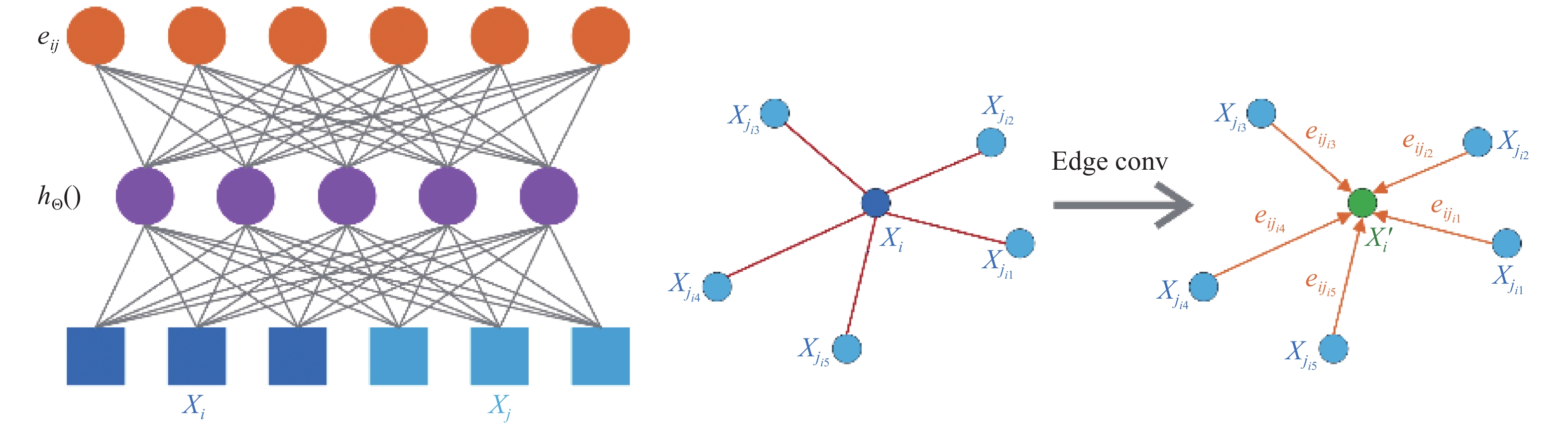
$ {X_i} = \left( {{x_i},{y_i},{{\textit{z}}_i}} \right) \subseteq {{\boldsymbol{R}}^{\boldsymbol{3}}} $ 表示经STN模块处理后点云数据中各个点的3D坐标,还应该包含相应的颜色、曲面法线等附加坐标。点集经KNN处理后,会生成一个点集结构的有向图。文中建立一个点集结构的有向图
$ G = (V,E) $ ,其中$ V = \left\{ {1,\cdots,n} \right\} $ ,$ \varepsilon \subseteq V \times V $ 分别表示顶点和边。在$ {{\boldsymbol{R}}^{\boldsymbol{3}}} $ 中$ G $ 为$ {X_i} $ 的自循环KNN特征图,目的是让每个节点指向自己。$ {e_{ij}} = {h_\Theta }({X_i},{X_j}) $ 定义为边缘特征,$ {h_\Theta } $ 为一组可学习非线性函数。最后,通过对每个点发出的所有与边相关联的边缘特征用于信道对称聚合操作来定义边缘卷积。第$ i $ 个顶点处输出的边缘卷积为:式中:
$ \Theta {\text{ = (}}{\theta _1}{\text{,}}\cdots{\text{,}}{\theta _M}{\text{,}}{{\varPhi }_1}{\text{,}}\cdots{\text{,}}{{\varPhi }_M}{\text{)}} $ 。把$ {X_i} $ 作为中心像素,$ \left\{ {{X_j}:(i,j) \in \varepsilon } \right\} $ 表示其周围补偿,边缘卷积特征提取详见图6,边缘卷积提取流程详见图7。
Figure 6. Schematic diagram of edge conv feature extraction

Figure 7. Edge conv feature extraction flowchart
在图6左边计算出
$ {X_i} $ 和$ {X_j} $ 边缘特征$ {e_{ij}} $ ,$ {h_\Theta }() $ 表示为全连接层实例化中的相关权重。在图7右边是边缘卷积层层提取特征并汇总成全局特征操作,通过聚合每个相连的顶点所发出的全部相关联的边来计算边缘特征并将其作为输出。结合全局几何形状结构,以
$ {X_i} $ 中心点坐标作为补偿,局部信息由$ {X_j} - {X_i} $ 获取,可表示为:利用公式(11)可以实现多层感知器的共享:
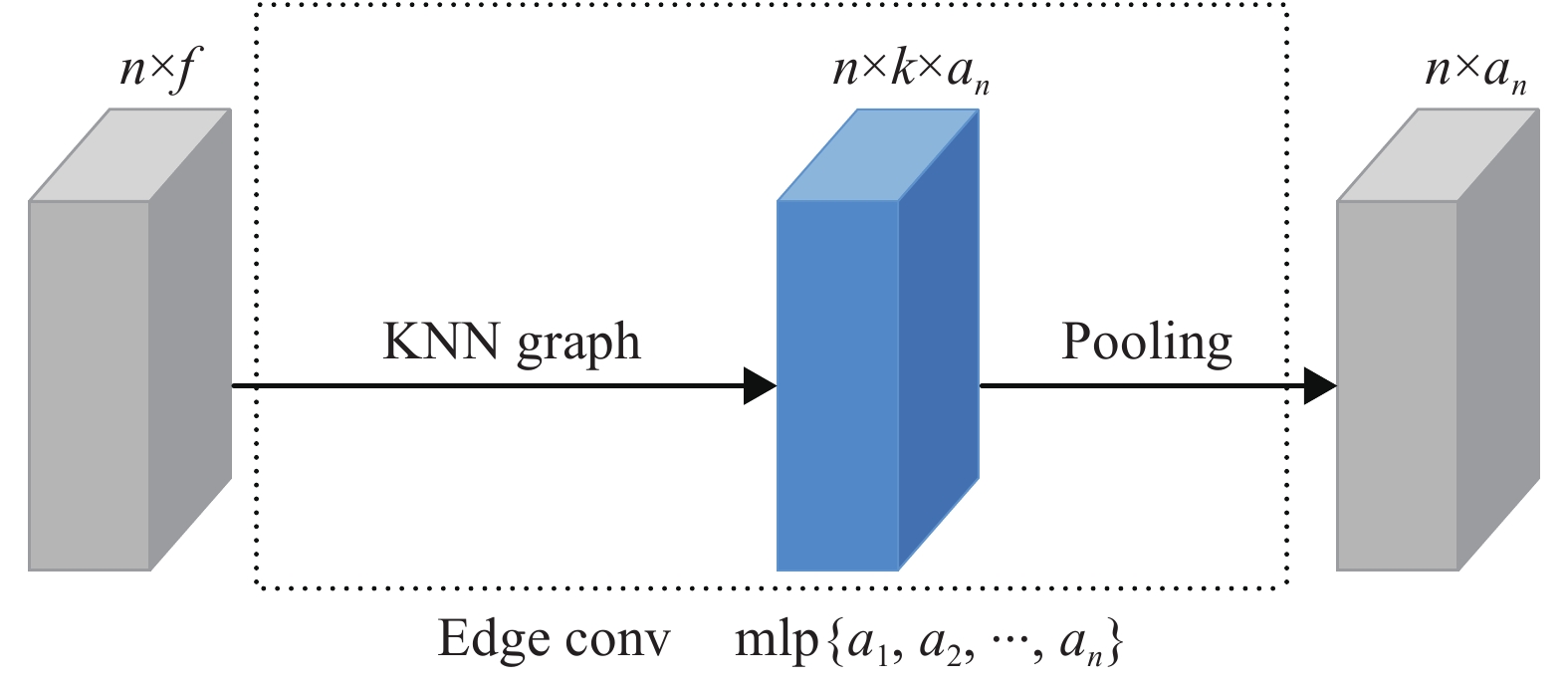
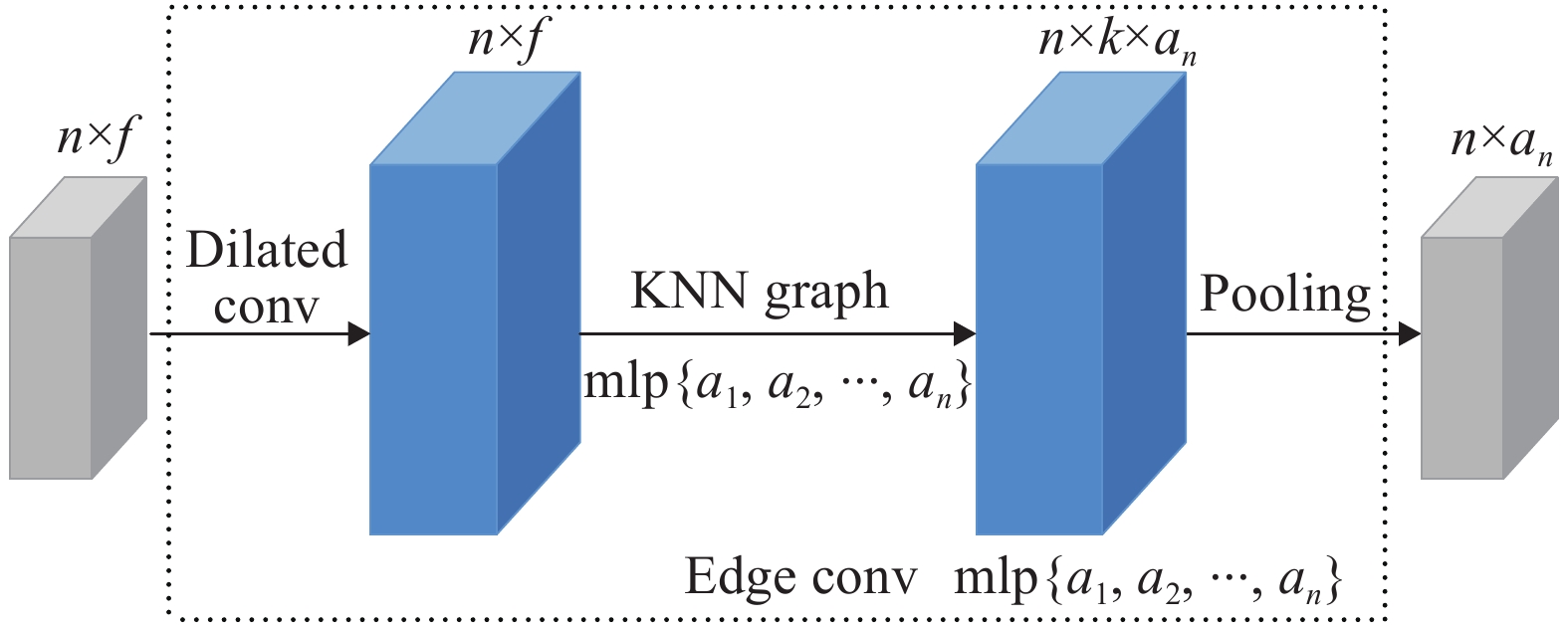
如图8所示为边缘卷积结构图,其中
$ n \times f $ 表示输入数据的张量,通过应用多层感知器(Multi-Layer Perceptron, MLP)来计算每个点的边缘特征,其中$ \left\{ {{a_1},{a_2},\cdots,{a_n}} \right\} $ 表示每层的神经元数量,$ n \times {a_n} $ 表示经相邻边缘特征之间池化后所生成的形状张量。
Figure 8. Edge Conv structure diagram
扩张卷积[12]是在标准的卷积核中注入空洞,以此来增加模型的感受野。相比原正常卷积操作,扩张卷积多了一个参数:扩张率,指的是卷积核的点的间隔数量,比如常规的卷积操作扩张率为1。扩张卷积不仅能够减轻池化层,还能更好地解决连续池化所造成信息丢失的问题。图9所示为扩张卷积的原理示意图,在网格中的结构化图形中内核为2,从左至右扩张率为1、2(底部扩张率相同)展开二维动态卷积。

Figure 9. Dilated conv in dynamic graph convolution
在文中的算法中,利用扩张卷积来扩大KNN采样的感受野,便于增大边缘卷积提取的范围。每提取一层全局特征,就要寻找其邻点并构造图结构。将扩张后的KNN和步长
$ d $ 作为图$ G = (V,E) $ 的离散率的输入,KNN越过$ d $ 个邻点,之后在返回区域为$ k \times d $ 的大小内,以l2为步长确定最近的$ k $ 个邻点。图10中,扩张卷积扩大了特征提取的范围,并不增加额外多余输入,它的内部结构与边缘卷积的结构基本一致。

Figure 10. Structure diagram of expanded edge conv
设
$ {N^{(d)}}\left( v \right) $ 为顶点的$ d $ 扩张邻域,如果$ ({u}_{1},{u}_{2},\cdots , {u}_{k\times d}) $ 为第一个序列的$ k \times d $ 最近相邻区域,则顶点$ ({u}_{1},{u}_{1+d},{u}_{1+2 d},\cdots ,{u}_{1+\left(k-1\right)d}) $ 是顶点$ v $ 的$ d $ 扩张相邻序列。扩张边缘卷积改善了KNN提取视野范围受限的问题,大大提高了全局特征的提取范围,增大了点云特征信息的数量。如图11所示,三组图像分别是经过扩张边缘卷积和边缘卷积特征提取后的物体可视化图像。

Figure 11. Comparison of feature extraction
根据图11中红色方框处标记可知,经扩张边缘卷积处理后的可视化图像,更能准确地标记分辨出物体的各部分组织特征,在灯台、飞机涡轮扇和桌子支杆处更准确的进行识别。而经边缘卷积处理后的可视化图像并不能准确地进行标识,这是由于边缘卷积的特征提取范围较小,在物体各部分组织提取时丢失了大量的几何信息,进而导致最终融合后丢失了大量的全局特征。物体各部分的几何信息给其特征提取提供了重要的信息描述,所以为尽可能避免几何信息的丢失,文中将扩张卷积和边缘卷积进行融合更完整地提取点云的整体特征。
-
在物体点云分类实验中,文中采用的是普林斯顿大学制作的用于3D模型识别的标准数据集ModelNet40[13],该数据集是一系列网格化的3D-CAD模型,包含40个类别的12311个CAD模型,其中有9843个训练模型,2468个测试模型。
在物体点云分割实验中,文中采用的是ShapeNet part[14]数据集。其中数据集包含16881个点云模型,共16个形状类别;其中14006个模型用于训练,2875个模型用于测试,不同类别的物体被分割成各个部分并且没有重叠,将每个模型中随机采样出2048个点进行物体分割实验。
-
为了保证实验的统一性和真实性,文中采用相同的实验平台、系统以及编译环境。基于Ubuntu和Cuda11.1建立的深度学习环境下进行,实验中所使用的深度学习网络框架和相关环境配置以及各部分模型参数详如表1所示。
Environment configuration Model parameters Name Configuration Name Value CPU Intel i7-10700 F Batch size 32 GPU RTX3090 Number point 1024 RAM 32 G Max epoch 250 Operation system Ubuntu18.04 Optimizer Adam Language Python 3.7 Learning rate 0.001 Learning framework TensorFlow GPU 1.15.0 Momentum 0.9 Table 1. Experimental platform configuration
-
为证明文中算法在处理点云分类任务上的优势,在ModelNet40[29]数据集上进行实验对比,其中对比算法包括:PointNet[5]、PointNet++[6]、DGCNN[8]、PointCNN[7] 、Pointwise[15]、Structural Relational Reasoning PointNet (SRN- PointNet)[16]、Graph Geometric Moments Net (GGM)[17]、Multi-scale Dynamic Graph CNN (MSDGCNN)[18]和EllipsoidNet (EllNet)[19]。通过对比评估准确度(Eval accuracy)和平均分类精确度(Avg class acc),来定量分析各算法的优越性。各算法分类实验结果详如表2所示。
Method Representation Input Eval accuracy Avg class acc PointNet[5] Points 1024×3 89.2% 86.2% PointNet++[6] Points(+normal) 1024×(3+3) 90.7% 87.8% DGCNN[8] Points 1024×3 92.2% 88.9% PointCNN[7] Points 1024×3 91.7% 88.5% Pointwise[15] Points 1024×3 91.6% 89.1% SRN-PointNet[16] Points 1024×3 91.5% 88.6% GGM[17] Points 1024×3 92.5% 89.0% MSDGCNN[18] Points 1024×3 91.8% 88.3% EllNet[19] Points 1024×2 92.6% 89.0% Ours Points 1024×3 92.7% 89.3% Table 2. Experimental comparison of various classification algorithms of ModelNet40[13]
表2中,除了PointNet++的输入为Points+normal的1024×(3+3)数据、EllNet输入的是1024×2二维点云数据,其余算法采用的均是标准Points的1024×3数据。文中算法在评估准确度和平均分类精确度数值上均优于其他9种算法,其中评估准确度为92.7%、平均分类精度为89.3%。PointNet和PointNet++虽然尽可能的提取点云的全局特征,但是只能考虑到全局和单个点的特征,缺少局部几何信息以及高级语义特征的描述,所以其分类的实验效果较差,最高的评估准确度仅为90.7%。尽管PointCNN、Pointwise以及SRN-PoinNet将PointNet算法进行了提升,分类实验的效果也大幅提升但是相较于文中的算法还是有一定的差距,最高的评估准确度也只有91.7%。在DGCNN和MSDGCNN这两个动态图卷积算法中,该实验结果有所提高,但局部有效信息仍有所丢失,最高的评估准确度仅为92.2%。在EllNet和GGM算法中,EllNet算法为提取潜在的局部特征,将点云数据的特征投影到一个二维椭球空间上,但是仍会造成部分隐式的高级语义特征丢失,而且这两个算法所提取的全局特征也会因为投影的过程造成丢失,最终导致评估准确度比文中算法低了0.1%。GGM算法是从局部点集入手,学习其几何特征,利用显式编码点构造几个特征进而生成表面几何特征,这种以局部特征构造全局特征的方法会对点云的真实几何信息造成丢失,而且点云隐式特征依然没能提取到,从而导致评估准确度仅有91.8%。相比而言,文中算法不仅提高了全局特征的提取范围,还通过局部提取到的高级语义信息和有效几何特征进一步完善了整体特征。通过分类实验对比,文中算法更具优越性。
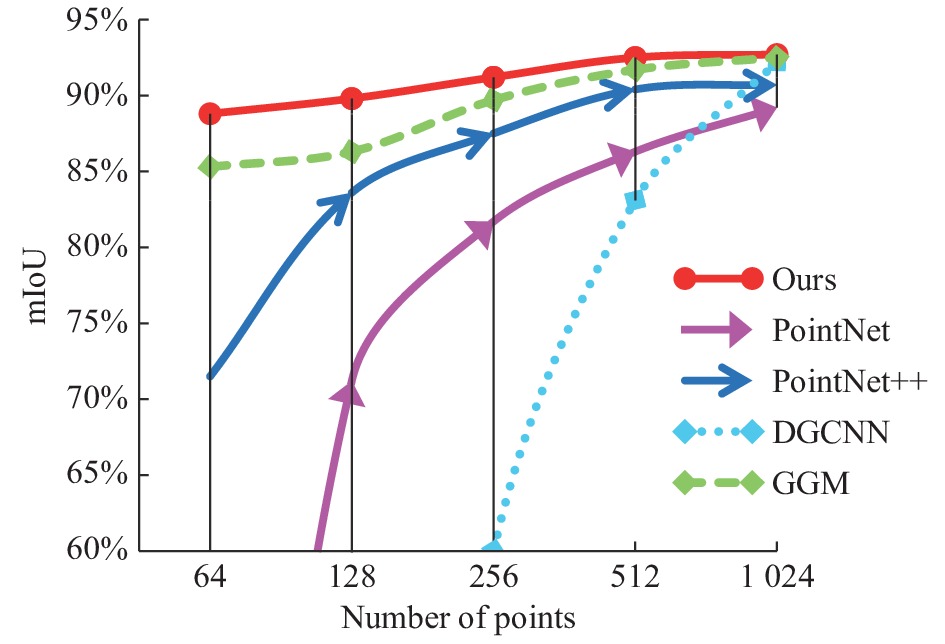
文中选取最具代表性的PointNet、PointNet++、DGCNN、GGM网络作为对比,通过测试点数为64、128、256、512、1024的稀疏点集数据,进一步测验该网络对点云数据集密度的稳定性如图12所示。

Figure 12. Relationship between points and classification accuracy
图12中,PointNet和DGCNN网络随着点集密度的增加,分类准确度提升的幅度极大,在处理稀疏点云数据时分类准确度极低。PointNet++网络在密度为64~128的点集之间分类准确度变化较大,在密度为128~512之间增长较为缓慢,当密度超过512时逐渐趋于稳定。GGM网络和文中方法的分类准确度整体增长幅度较小,当密度大于512之后分类准确度基本保持不变,但各点集密度的分类准确度都要高于GGM。文中方法不随点集的密度变化而过度影响分类准确度,在点集密度呈倍数增减的状态下分类准确度的整体波动范围不超过4%,而且不同密度的点集经本方法处理后的分类准确度仍然高于其他方法。
为了更好地测评本网络的性能,选取更具代表性的PointNet、PointNet++、DGCNN、PointCNN作为对比方法,通过测评模型大小、测试耗时及精度进行定量分析。从表3可以清晰地看出该网络复杂度低且模型轻量化、耗时较短,在分类准确度上更是优于其他算法。
-
在分割实验中,采用ShapeNet part[14]数据集来评估各算法的物体分割效果,与分类对比算法保持一致。
利用各个类别的IoU(%)和总体分割精度mIoU(%)作为定量分析的评价度量。其中IoU的求值表达式为:
各算法分割测试结果如表4所示,通过实验数据可知,经文中算法处理后的数据集物体分割总体分割精度mIoU(%)的值是85.5%,而且在16个类别中,文中算法有一半以上类别的精度达到了最优效果。虽然在mIoU数值上文中相比较PointCNN相差了0.6%,但其算法需要增加信息量来提高精度。相比而言文中算法处理点云数据更简洁,计算成本也比较低。
Method mIoU Shapes IoU Plane Bag Cap Car Chair Earcup Guitar Knife Lamp Laptop Motor Mug Pistol Rocket Skate Table PointNet[5] 83.7% 83.4% 78.7% 82.5% 74.9% 89.6% 73.0% 91.5% 85.9% 80.8% 95.3% 65.2% 93.0% 81.2% 57.9% 72.8% 80.6% PointNet[6] 85.1% 82.4% 79.0% 87.7% 77.3% 90.8% 71.8% 91.0% 85.9% 83.7% 95.3% 71.6% 94.1% 81.3% 58.7% 76.4% 82.6% DGCNN[8] 85.2% 84.0% 83.4% 86.7% 77.8% 90.6% 74.7% 91.2% 87.5% 82.8% 95.7% 66.3% 94.9% 81.1% 63.5% 74.5% 82.6% PointCNN[7] 86.1% 84.1% 86.4% 86.0% 80.8% 90.6% 79.7% 92.3% 88.4% 85.3% 96.1% 77.2% 95.3% 84.8% 64.2% 80.0% 83.0% Pointwise[15] 85.1% 82.9% 80.7% 87.8% 76.6% 90.8% 79.2% 91.0% 86.6% 83.3% 95.3% 71.9% 94.4% 80.9% 62.0% 75.1% 82.5% SRNPNet[16] 85.3% 82.4% 79.8% 88.1% 77.9% 90.7% 69.6% 90.9% 86.3% 84.0% 95.4% 72.2% 94.9% 81.3% 62.1% 75.9% 83.2% GMM[17] 85.2% 83.9% 82.8% 88.0% 79.8% 90.7% 76.8% 91.3% 87.6% 82.6% 95.5% 66.6% 94.8% 81.8% 62.6% 73.8% 82.6% MSDGCN[18] 85.4% 83.7% 84.7% 87.5% 77.0% 90.8% 68.2% 91.5% 86.5% 96.0% 95.5% 72.0% 95.1% 83.4% 61.9% 77.4% 82.9% Ell-Net[19] 85.0% 82.8% 81.5% 87.6% 76.8% 90.6% 78.8% 90.8% 86.8% 86.9% 95.1% 71.8% 94.2% 80.8% 61.8% 75.0% 82.2% Ours 85.5% 84.3% 85.8% 88.1% 80.0% 90.8% 79.5% 91.6% 88.2% 91.6% 95.8% 76.7% 96.1% 82.6% 65.6% 81.2% 82.8% Table 4. Local segmentation test results of each algorithm on the ShapeNet Part[14] data set
ShapeNet Part数据集共分为18个类别,依次从18个类别里随机抽取一个例子进行可视化展示,并与PointNet[5]算法及标准实例图(Ground Truth)进行比较,详情如图13所示。

Figure 13. Visualization of object segmentation test results
如图13所示,依据红色方框标记处的各类别分割可视化对比展示。文中算法的可视化结果基本接近于标准分割图例,更接近于真实分割效果。然而经PointNet算法分割后的可视图出现了较为严重的错误现象,例如bag中的手袋部分不能进行准确的分割标记,这是由于PointNet算法不能完整地提取点云全部特征所导致的。根据主观可视化视图对比和客观数据对比,文中网络能大幅度提高物体分割的准确率。
为更好地验证文中算法能够应用于更多复杂的点云数据,对稀疏点集物体,大型复杂场景(其中大型复杂场景包含遮挡场景和遮挡物体数据)进行分割测试。如图14、15所示,分别表示稀疏点集物体和大型复杂场景的分割可视化结果图。文中算法不仅能够在权威的ShapeNet part[14]标准数据集下进行准确分割,还能够精准地分割稀疏点集和大型复杂场景,分割的效果更具优越性。

Figure 14. Object sparse point map segmentation results

Figure 15. Complex scene segmentation results
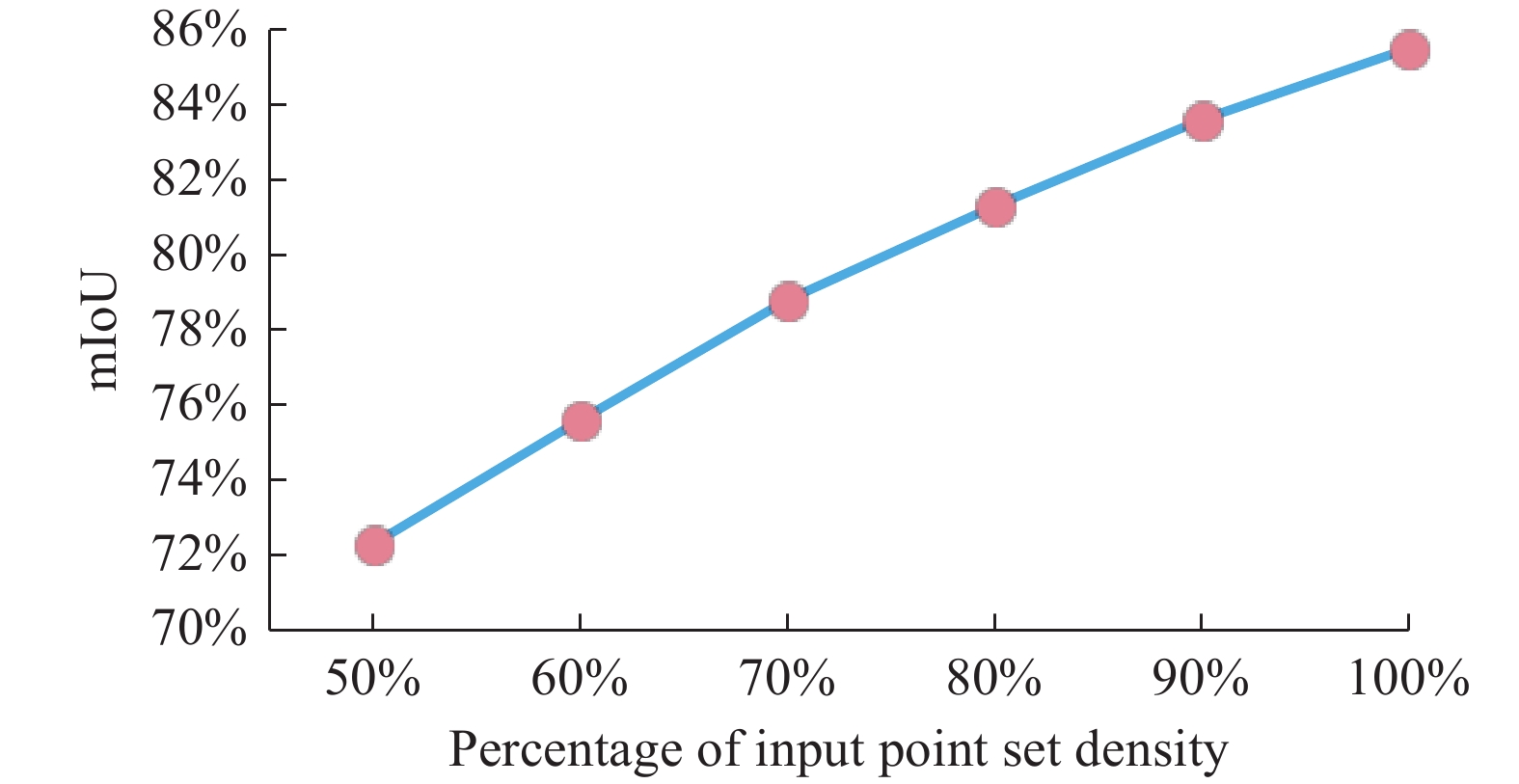
图16所示为点集密度与分割精度的关系,图17为不同点集密度下的分割可视图。文中分别从点集的不同位置减少点的数量并依次进行分割精度的测试,实验结果表明,随着点数的增多分割的精度也逐渐增大,当物体点集数量为整体密度的100%时分割精度达到最大。该算法在分割点集密度不足100%的数据时仍能将物体的各部分信息表示出来,由此可见在处理残缺或遮挡点云数据时算法依然可以达到较好的准确度。

Figure 16. Rrelationship between density and accuracy

Figure 17. Segmentation viewable under different point set densities
-
为了优化网络,寻求最佳参数组合,进行消融实验分析,依然采用标准的ModelNet40[13]数据集进行实验操作。
局部采样的关键在于感受野的大小,最佳的感受野能更好的对局部特征进行感知。感受野过大会造成特征提取的不细致,而感受野过小则会造成细节信息的丢失。感受野的大小取决于邻近点的数量,通过测试不同数量的最近邻点对结果的影响来进行实验分析,进而得到最佳的
$ K $ 值。由表5可知,当
$ K $ 值为20时分类评估准确度最高,表明当前感受野的大小合适,局部特征提取最佳。当$ K $ 值大于20时,分类评估准确度开始下降。实验结果表明,当最近邻点数为20时,局部感受野最佳,能够尽可能的将局部信息提取完整。KNN point number Avg class acc Eval accuracy 16 89.5% 91.4% 20 89.8% 92.7% 25 89.1% 91.3% 30 88.6% 91.1% 32 88.5% 90.8% Table 5. Analysis of the best
$ K $ value在文中网络中,扩张边缘卷积模块和KNN-VLAD模块是提取点云全局几何信息特征和局部高级语义特征的模块,可以大幅度提升网络的性能。扩张边缘卷积模块通过扩大特征提取的范围,进一步增加提取点云各处的几何信息数量,最终汇总成全局特征。KNN-VLAD模块通过KNN采样获取点与点之间的联系,VLAD模块利用已经提取的低级语义信息来描述高级语义信息,补偿全局提取特征时遗漏的有效信息。
如表6所示,若网络中仅含扩张边缘卷积模块时,此时只能全局特征的提取,缺乏重要的局部特征的补偿,由于整体特征不完整导致分类评估准确度仅有92%。如果网络中仅含KNN-VLAD模块时,由于只有对局部特征进行细致提取而缺乏全局特征的提取及汇总,其分类评估准确度只有90.8%。而当2个模块同时工作时才能提高网络的性能,分类评估准确度才能达到最高,其数值为92.7%。经消融实验分析,证明了上述模块的重要性及有效性。
Dilated-Edge conv KNN-VLAD Avg class acc √ × 92.0% × √ 90.8% × √ 92.7% Table 6. Analysis of module impact
-
针对目前物体点云分类分割网络提取点云特征不完整的问题,文中提出了基于语义信息补偿全局特征的物体点云分类和分割的网络。首先将待处理的数据输入至STN模块,使数据转换到对齐的规范空间中,保证输入数据的排列方式不变。其次,通过扩张边缘卷积模块层层提取点云数据的各部分特征,并汇总成全局特征。在局部特征的提取中,采用KNN-VLAD模块将提取到的低级几何信息来尽可能地描述高级语义特征,这些特征和有效信息用于补偿全局遗漏的特征,这两个模块保证了点云特征的完整性。最后,将局部特征和全局特征融合生成整体特征。实验结果表明,文中算法不仅能够有效地提升物体点云数据的分类和分割的准确度,而且在处理稀疏、残缺及复杂场景数据时仍能保持准确度的稳定;通过实验对比,文中算法的网络结构复杂度低、耗时短,相较于其他算法更具优越性。
Object point cloud classification and segmentation based on semantic information compensating global features
doi: 10.3788/IRLA20210702
- Received Date: 2022-01-20
- Rev Recd Date: 2022-02-25
- Publish Date: 2022-08-31
Fund Project:
National Key Research and Development Program of China(2018 YFB1403303)
-
Key words:
- semantic information /
- 3D model classification, segmentation /
- feature extraction /
- deep learning
Abstract: 3D point cloud data processing has played an essential role in object segmentation, medical image segmentation, and virtual reality. However, the existing 3D point cloud learning network has a small global feature extraction range and cannot obtain local high-level semantic information, which leads to incomplete point cloud feature representation. Aiming at these problems, a classification, and segmentation network of object point cloud based on semantic information compensating global features was proposed. Firstly, align the input point cloud data to the specification space, and perform the preprocessing of the input conversion of the data. Then, the expanded edge convolution module was used to extract the features of each layer of the converted data and superimpose them to generate global features. In the local feature extraction, the extracted low-level semantic information was used to describe the high-level semantic features and effective geometric information, which was used to compensate for the missing point cloud features in the global features. Finally, the global feature and local high-level semantic information were combined to obtain the overall feature of the point cloud. The experimental results show that the method in this paper is superior to the current classic and novel algorithms in classification and segmentation performance.









































































































 DownLoad:
DownLoad: