





-
网络业务的激增对骨干网传输带宽提出了更高的要求。如何在有限资源网络中为业务选择合适的路由和分配优化的波长对于提升网络资源的利用效果、优化管理和灵活控制都有较大的影响。所以路由与波长分配(Routing and Wavelength Assignment,RWA)成为光传送网中的核心问题之一[1-3]。
RWA问题一般被分为路由问题和波长两个方面,首先选取合适的路由作为链路,然后为链路分配波长[4-6]。常用的路由算法有最短路径算法(Shortest Pathes,SP)、K条最短路径算法(K Shortest Pathes,KSP);其中SP根据源节点-目的节点计算最短路径,当业务请求到来选择最短路径路由。这种方法计算复杂度低,但会导致网络阻塞率高。KSP是在SP的基础上,在源节点-目的节点计算K条路径并且按照距离排序。当业务到达时,可按照优先级顺序选择可用路由。常用波长分配算法有随机分配 (Random Assignment, RA)、首次命中 (First Fit, FF)等。其中RA是在可用波长的集合随机选择一个波长传输资源,该算法实现简单,被使用波长的随机性较大。而FF按照优先级搜索可用波长,使用首次找到可用的波长传输信息。FF计算开销较小、阻塞率较低。参考文献[7]对解决RWA问题波长分配的常用方法做了对比实验,仿真表明波长分配算法对RWA问题的解决影响较小,因此FF是光网络中目前应用较多的典型算法。
由于目前的云计算、数据互联等新业务呈现动态特性,上述路由方法由于缺乏灵活性不再适用,需要根据业务特性快速按需部署网络资源,并借助智能算法为光网络的路由选择提供灵活的优化管理与控制方案,软件定义网络(Software Defined Network,SDN)与深度强化学习的思想可以为上述方案实施提供支持。
近几年,基于机器学习的光网络路由和波长智能分配算法引起了学者的广泛关注。参考文献[7]提出一种遗传算法解决光网络中RWA问题,较传统算法具有更低的的网络阻塞率。参考文献[8]提出一种蚁群RWA算法,实现了卫星光网络的负载均衡,但是所提出的蚁群算法易陷入局部最优,收敛速度较慢。参考文献[9]考虑卫星光网络传输延迟和波长连续性限制,提出改进蚁群算法的RWA方法,降低了计算复杂度,但是也增加了阻塞率。参考文献[10]使用监督学习的机器学习方法解决RWA问题,将RWA问题映射为分类问题,该算法大大减少了生成RWA策略的计算时间,但训练数据集难以得到。
自2015年开始,深度强化学习已用于解决通信网络的优化问题[11]。参考文献[12]中,作者针对空中移动无线通信节点与水面通信节点信息交互的应用场景,提出基于深度强化学习的方法引导空中无线通信节点移动路径,实现最小代价水面通信节点覆盖。参考文献[13]中,作者针对通信组网对抗中干扰资源分配的优化问题,提出了一种基于最大策略熵深度强化学习的干扰资源分配方法。参考文献[14]中,作者提出一种基于深度强化学习算法用于解决光传送网中路由、调制、波长和端口分配问题,目的是降低成本。但是该算法处理复杂的拓扑时,由于可用的路由路径较多,将导致模型训练时间较长。在参考文献[15]中,作者提出一种基于深度强化学习的路由和资源分配算法,该算法可以选择跳数最小的路径和数量最少的波长转换器,降低光网络运维成本,简单实验拓扑验证算法可以达到预期目标,但实验所需的网络拓扑及评价指标需要进一步扩展。在参考文献[16]中,作者针对弹性光网络提出一种基于深度强化学习的路由-模式-频谱分配算法,根据业务需求动态分配带宽,进而提高频谱利用率,有效降低弹性光网络中业务请求的阻塞概率,对光传送网中RWA问题的解决有一定借鉴意义。
针对光网络中的路由选择和波长分配问题,借鉴弹性光网络中频谱优化的思想,提出一种深度路由波长分配算法(Deep Routing and Wavelength Assignment, DeepRWA),该算法采用SDN框架灵活控制光传送网络的路由选择和波长分配,基于深度强化学习策略实现RWA的智能化处理。深度强化学习使用异步优势行动-评论算法(Asynchronous Advantage Actor-Critic, A3C)算法并考虑波长使用情况选择路由;在此基础上使用FF实现波长分配,使路由阻塞率最小,提升资源利用率。
-
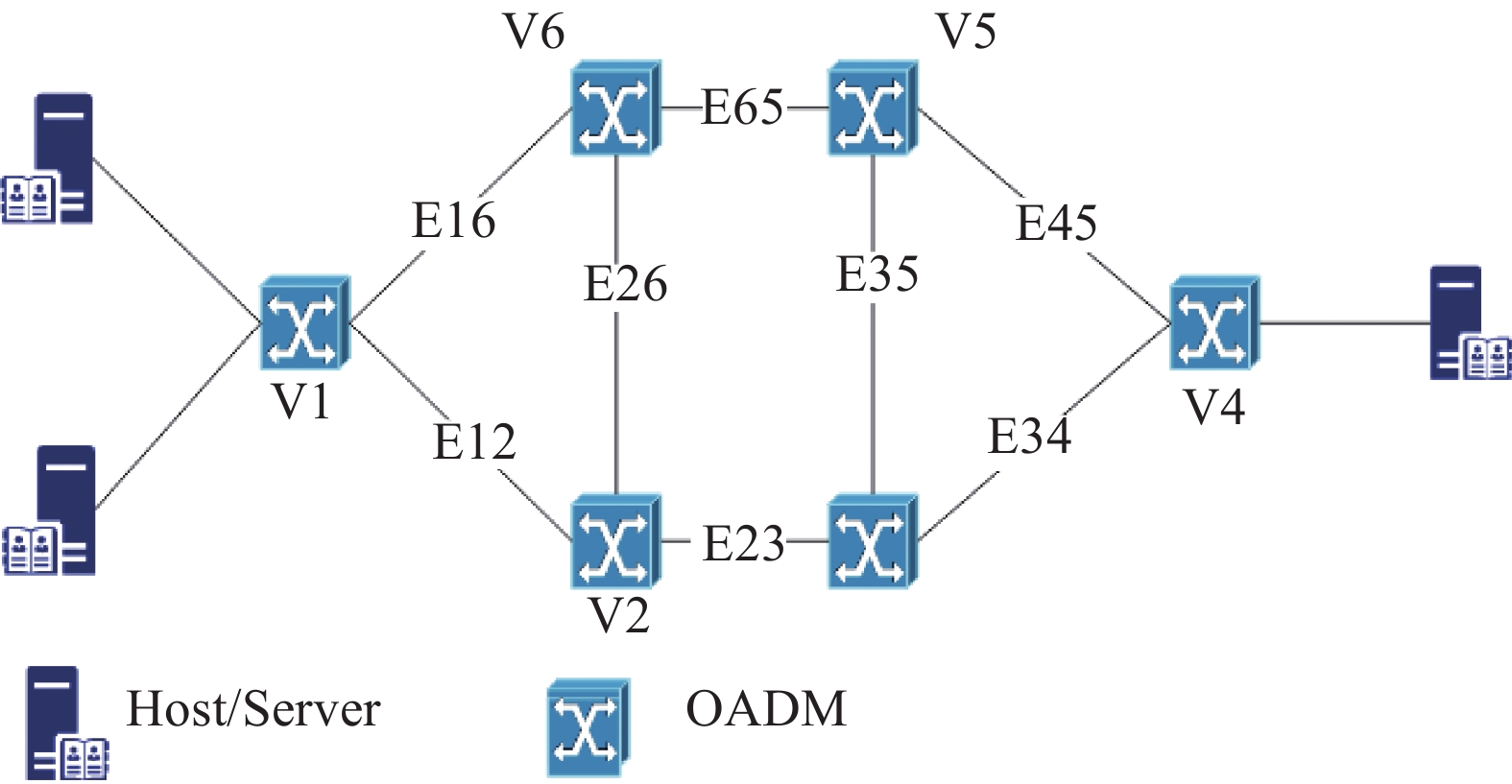
光传送网由光分叉复用器(Optical Add/Drop Multiplexers,OADM)和链路构成。光传送网连接模型可使用图结构G(V, E, F)表示,如图1所示,其中V和E表示拓扑的节点(主要是光分插复用器OADM)和链路,F={Fe, f | e, f}表示某条光纤链路e中的波长f使用情况。空闲波长分布情况用
$f=\left\{z_{\,\,\,\,\,\,\, k}^{1, j}, z_{\,\,\,\,\,\,\, k}^{2, j}\right\}$ 表示,$z_{\,\,\,\,\,\,\, k}^{1, j}$ 表示第k条路由第j段波长可用波长的数量;$z_{\,\,\,\,\,\,\, k}^{2, j}$ 表示第k条路由第j段波长第一个可用波长的索引。当光网络处于工作状态时,业务由主机发出,服务器对服务做出响应。把一个从源节点到目的节点的光路请求设为Rt(o, d, τ), 其中o和d表示光路请求的源节点和目的节点,τ表示光路业务请求的持续时间。
Figure 1. Optical transport network model
RWA包含路由选择和波长分配两个子问题,路由选择是在业务的源节点、目的节点之间选择一条合适的物理路径进行数据传输,以最小化阻塞率为目标;波长分配就是路由选择结果确定之后为业务请求分配波长,主要以提高波长利用率为目标,即提高已用波长数在总波长数的比例。在波长分配阶段,需要遵循两个原则:(1)波长一致性限制, 连接源-目的节点的光通道必须分配相同的波长。(2)不同波长限制,所有使用同一条光纤链路的光通道都必须分配不同的波长。
根据应用场景的不同,RWA工作方式主要分为两种:静态RWA与动态RWA。静态RWA主要解决固定的业务请求下如何最小化网络成本和网络资源使用(例如所需波长数最少)的问题,即提高资源利用率。动态RWA主要解决在业务请求随机到达的情况下如何最小化业务的阻塞率,并提高网络资源利用率的问题。目前光传送网中动态业务较多,文中针对动态RWA问题进行研究。假设光网络拓扑的节点不具备把光信号的波长转换为一个不同的波长,即波长转换功能,因此光路请求需要服从波长一致性限制。
-
文中提出的基于强化学习的深度路由波长分配算法DeepRWA总体结构如图2所示,算法采用SDN架构,由光网络模块、 控制器、强化学习模块三部分组成。SDN本地控制器作为核心,首先根据数据平面获得网络状态和光路请求,利用深度强化学习算法生成RWA策略然后下发至数据平面。光网络模块主要由光分叉复用器作为节点,节点间相互连接形成拓扑;SDN控制器是光网络模块和强化学习模块的桥梁,可以感知光网络信息、波长使用情况、业务请求信息,为光网络提供高效的路由与波长分配策略;强化学习模块利用控制器收集的信息进行训练,把生成包括路由路径和选用波长的动作发送至控制器模块。DeepRWA工作过程是通过SDN智能控制光传送网的数据平面, DeepRWA具体实现步骤如下:

Figure 2. Structure of DeepRWA
(1) SDN本地代理首先收到主机发出的光路请求Rt;
(2) SDN控制器获得网络拓扑信息和光路请求信息,调用特征处理模型产生DeepRWA的状态信息,其中包括可选路由和每条路由的波长使用信息;
(3) DeepRWA强化学习模块通过神经网络读取状态st ,利用A3C算法迭代训练,将神经网络的输出作为RWA策略发送至SDN控制器;
(4)控制器将RWA策略下发至本地代理,由本地代理执行相应的路由和波长分配策略,即DeepRWA的动作;
(5)奖励系统将获得以往的历史奖励作为反馈和生成DeepRWA的即时奖励rt;
(6)存储即时奖励、动作和状态三个元素数据至经验池;
(7)利用经验池的数据训练策略神经网络和价值神经网络,更新神经网络的参数,利用策略神经网络获取RWA策略。RWA策略是选择策略神经网络中概率最大的动作。
-
文中提出DeepRWA的核心是基于强化学习的路由波长优化算法,而强化学习关键是设计状态、动作和奖励,文中具体设计如下:
(1)状态:针对拓扑中的单业务请求,使用特定的矩阵表示状态st信息和候选路径的波长使用情况,文中状态设定如图3所示,其中图3(a)为光网络拓扑;图3(b)为光网络链路的波长使用示意图,定义状态为1×(2 |V|+1+2JK)大小的矩阵,如公式(1)所示:

Figure 3. Example of state
式中:o、d和τ表示业务请求的源节点、目的节点和服务时长;k∈[1, 2, ··· , K],j∈[1, 2, ··· , J],K为业务请求的所有候选路由数(如图3(a)虚线部分),J表示某条路由所有可用波长段(单个可用波长段至少包含一个可用波长且波长段内的所有波长位置连续,如图3(b)中白色部分),V表示拓扑的节点数。候选路由数目的不同会导致状态的不同,因此需采用一个固定的候选路由数目。强化学习可以通过探索多条候选路由获得更大的收益,然而收敛时间也会更长。候选路由数太少,强化学习的收益较小;候选路由数太多,算法收敛速度慢,文中参考文献[15]的设置,即K=5。
$\left\{z_{\,\,\,\,\,\,\, k}^{1, j}, z_{\,\,\,\,\,\,\, k}^{2, j}\right\}$ 表示业务请求某条候选路由的未占用波长分布情况,$z^{1, j}_{\,\,\,\,\,\,\, k},$ 表示第k条路由第j段波长可用波长的数量,$z^{2, j}_{\,\,\,\,\,\,\, k},$ 表示第k条路由第j段波长第一个可用波长的索引。具体实例见图3(a)中,假设业务有两条路由可选,1-2-4为路由1 (k=1),1-3-5-4为路由2 (k=2)。图3(b)中两条路由1、2的波长使用情形分上下两部分,上方路由1的第1段波长可用波长数量$z_{\,\,\,\,1}^{1,1}= 3$ ,路由1的第1段波长可用波长集合的起始索引$z_{\,\,\,\,1}^{2,1}=0 $ ;路由1的第2段波长可用波长数量$z_{\,\,\,\,1}^{1,2} =3$ ,路由1的第2段波长可用波长集合的起始索引$z_{\,\,\,\,1}^{2,2}=9 $ ;下方路由2第1段波长的可用波长数量$z_{\,\,\,\,2}^{1,1}=4$ ,路由2第1段波长的可用波长集合的起始索引$z_{\,\,\,\,2 }^{2,1}=2$ ;路由2第2段波长的可用波长数量$z_{\,\,\,\,2}^{1,2}=4$ ,路由2第2段波长的可用波长集合的起始索引$z_{\,\,\,\,2}^{2,2}=8 $ 。因此图3的状态表示为:$S_{t}= \left\{o, d, \tau , z_{\,\,\,\,1}^{1,1} \sim z_{\,\,\,\,1}^{2,2}, \quad z_{\,\,\,\,2}^{1,1} \sim z_{\,\,\,\,2}^{2,2}\right\}$ 。(2)动作:动作空间需要对光网络中业务的路由和波长进行部署,每一个动作就是代表一种路由与波长分配方案。对于一个业务请求,DeepRWA算法从光网路拓扑的K条候选路径选择一个路由路径,根据状态计算可选波长数I,从I个可选波长选择一个可用波长传输数据,因此动作空间包含K*I个动作。
(3)奖励:奖励的设定对算法的收敛速度和动作决策都有很大影响。由于动态RWA问题的优化目标是最小化阻塞率,所以用业务的成功率衡量该动作的价值。即时奖励作为一个标记,记录当前业务请求是否成功。DeepRWA算法如果成功地使一个业务通过光网络传输,即路由与波长分配成功,此时即时奖励rt=1,否则rt=−1。即时奖励为1时,表明代理在状态S下执行动作a策略会更好,有助于策略的收敛;即时奖励为−1时,表明代理在状态S下执行动作a策略比较差,不利于策略的收敛。DeepRWA中神经网络不断迭代使累积收益Γ最大化,累积收益如公式(2)所示:
式中:γ∈[0,1]是未来收益的折扣因子;t'表示未来某个时刻;t表示当前时刻。
-
文中从阻塞率、资源利用率、策略熵、价值损失和运行时间及收敛速度五个方面评价DeepRWA算法的性能。并与现有的算法KSP-FF对比,验证所提出算法的有效性,借鉴参考文献[16]的参数设置,KSP-FF算法的备选路径设为5条,即K=5,下面实验中KSP-FF参数均采用上述设置。
-
仿真实验采用如图4所示的14节点NSFNET拓扑,链路间的数字代表节点间的距离(单位:km)。实验采用动态的业务模型,业务服从泊松分布,服务时间遵循指数分布,具体参数如表1所示,软件配置操作系统选用Ubuntu16.04,GPU为NVIDIAGeforce1080 Ti,CPU为i7-6700 k,程序设计采用python3.7,tensorflow版本为1.14.0。

Figure 4. 14-node ¬NSFNET topology
Parameters Value Average arrival time of dynamic service/s 1/12 Continuing times of dynamic service/s 13 Available wavelength of channel 18 Table 1. Serve parameters of simulation experiment
-
(1)阻塞率
动态RWA问题的目标是最小化阻塞率,对比了DeepRWA算法和KSP-FF算法阻塞率指标随业务数变化情况。图5给出了上述两种算法随着业务数增加的变化曲线。从图5可以看出,业务请求数较小时DeepRWA阻塞率较大,为0.16左右。这是因为业务请求数较少时,DeepRWA训练次数较少,没有学习到理想的路由与波长分配策略。当业务请求数达到370000个后,经训练的DeepRWA路由和波长分配方案的阻塞率降到0.01,比KSP-FF算法的阻塞概率近似低0.06。原因是KSP-FF寻找路由只考虑最短路径,遇到无可用波长的链路就会发生阻塞;而DeepRWA在选路过程中考虑路径的跳数及波长占用情况,综合考虑选择一条路径,尽可能避开了拥塞链路。因此,DeepRWA较KSP-FF算法具有更低的(业务)阻塞率。

Figure 5. Curve of blocking rate
(2)资源利用率
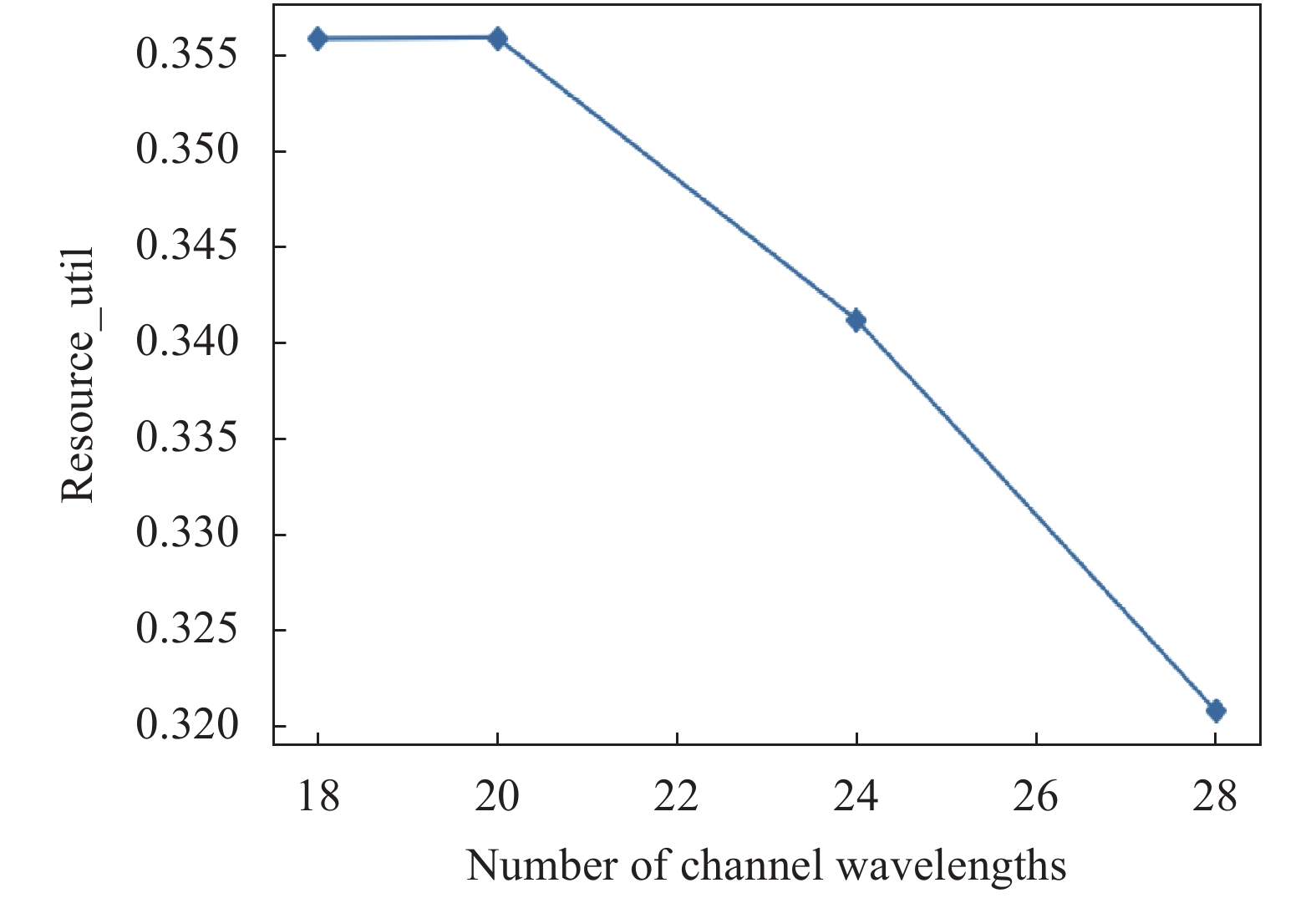
资源利用率表示被业务利用的资源占总资源的比例,资源利用率越大,代表网络中被充分利用,算法性能会更好。图6比较了DeepRWA算法和KSP-FF算法资源利用率随业务数变化的性能曲线。从图6可以看出,DeepRWA算法资源利用率在训练过程中逐步提高最后趋于稳定。起初资源利用率较低且波动较大,因为随着业务请求数增多,要想服务这些业务,就要不断地分配波长,网络的资源利用率必然呈上升趋势。在训练过程中,业务数较小时资源利用率为0.51,当业务数达到150000后,DeepRWA资源利用率上升至0.59,表1中设定的18个波长平均有10.6个波长被利用;而在KSP-FF算法下,设定的18个波长中平均有10.1个波长被利用。可见DeepRWA的路由和波长策略使光网络中资源利用率超过了KSP-FF算法。图7表示实验环境的其它参数不变,资源利用率随着信道波长数变化关系曲线图。随着信道波长数增加,资源利用率逐渐降低。由于业务强度一定,当信道波长数增加时,链路间空闲信道明显增加。根据资源利用率的定义,它会逐渐降低,使网络拥塞问题有所改善。

Figure 6. Curve of resource occupancy

Figure 7. Curve of resource utilization rate vs. channel wavelength
(3)策略熵
图8描绘了DeepRWA算法随着业务强度增加策略熵的变化曲线,熵值的变化可以反映所提出的算法是否进行了有效的学习。熵值越大说明算法得到的路由和波长策略不确定性越强;策略熵收敛表明算法的随机性降到最低,模型已经训练完成。当业务强度较小时,熵值较大,生成的路由与波长决策随机性较大;随着业务请求数量的增加,当该算法通过3000000个业务请求后,策略熵收敛,熵值从1.5下降至0.15,说明DeepRWA已经学习到一些规则并可以做出随机性相对较小的路由与波长决策。

Figure 8. Curve of policy entropy
(4)价值损失
价值损失函数用于计算价值神经网络预估值和真实值的差距,从而指导下一步的训练向正确的方向进行。价值损失描述的是累积收益与价值函数预测值的接近程度,用于评价算法的优劣。图9描述了价值损失随着训练过程的变化曲线,训练过程中价值损失逐渐降低,训练逐渐稳定。当业务数较少时,选择的路由与波长策略的预测值与累积收益差距较大。随着业务数的增加,训练后算法的预测值逐渐接近于累积收益,当通过450000个业务请求后训练算法的价值损失减少至2.5左右,预测值和累积收益比较接近,表明采取的路由与波长策略比较合适。

Figure 9. Curve of value Loss
(5)运行时间及收敛速度
运行时间是衡量算法时间复杂度的评价指标,运行时间越短表明算法的时间复杂度越小、适应性越好。针对单个业务请求,在业务服从泊松分布、到达率和服务时长的设置同表1时,对比了DeepRWA算法和KSP-FF算法运行时间随波长数变化情况,如图10(a)所示。由图10(a)可知,当信道波长数增加时,两种算法运行时间均明显增加。因为当信道波长数增加时,路由与波长分配策略复杂度增加。但是,随波长数增加,DeepRWA算法运行时间增长的速度明显慢于KSP-FF。当信道中包含18个波长时,与KSP-FF算法相比,DeepRWA算法运行时间增加了0.12 ms;当信道中包含的波长数增加至45时,两种算法的运行时间大致相同;之后,DeepRWA算法运时间优势逐渐明显,当信道中包含的波长数增加至58时,与KSP-FF算法相比,DeepRWA算法运行时间减少了0.07 ms。因此,DeepRWA较KSP-FF算法更适应于波长数较多的光网络。

Figure 10. Algorithm’s execution time and converage speed
算法的收敛速度反应了智能体使网络达到最低阻塞率需要的训练时长,也即算法收敛需要的业务数量。使用多线程训练神经网络,线程数的不同也会影响网络收敛速度。文中采用A3C算法,业务服从泊松分布,到达率、服务时长和信道波长数的设置同表1,仿真得到算法收敛所需业务数随线程数变化曲线如图10(b)所示,可以看出当线程数增加时,算法训练至收敛需要的业务数呈指数式减少。当线程数为2时,算法需要690000个业务进行训练;当线程数增加至8时,算法收敛所需的业务数已减少至190000。由此可知,在CPU/GPU支持的最大线程范围内,增加线程数可以明显减少算法的训练时间。
-
为了适应大量动态业务的需求,针对光网络中的RWA问题进行研究,考虑阻塞率、资源利用率两个目标提出一种基于强化学习的路由波长分配算法DeepRWA,采用SDN网络架构实现光网络灵活控制,通过强化学习实现路由选择和波长分配的优化。针对路由选择问题,结合链路上的波长使用情况,使用A3C算法选择合适的路由,使得阻塞率最小;针对波长分配问题,使用首次选中算法选择波长。利用NSFNET网络拓扑下进行了仿真实验,结果表明文中所提的DeepRWA算法阻塞率更低,改善了资源利用率,提升了网络的性能;当链路波长数较多时,与KSP-FF算法相比,文中所提DeepRWA算法运行时间更短,适应性更好。后续结合实际网络和业务进行进一步的研究和测试,为实际应用提供有力的支持。
Optimization of routing and wavelength optimization algorithm for optical transport network based on reinforcement learning
doi: 10.3788/IRLA20220084
- Received Date: 2022-02-07
- Rev Recd Date: 2022-07-23
- Publish Date: 2022-11-30
-
Key words:
- optical transport network /
- routing and wavelength optimization /
- reinforcement learning /
- routing selection /
- wavelength assignment
Abstract: Aiming at the routing and wavelength problems of dynamic services in optical transport network, a deep routing wavelength assignment algorithm based on reinforcement learning is proposed. The algorithm is based on a software defined network architecture, flexibly adjusts and controls the optical transport network through reinforcement learning, and realizes the optimization of the optical network routing wavelength assignment strategy. For the problem of routing selection, combined with the wavelength usage on the link, the A3C algorithm is used to select the appropriate route to minimize the blocking rate; for the problem of wavelength assignment, the first fit algorithm is used to select the wavelength. Considering multiple indicators such as blocking rate, resource utilization, policy entropy, value loss, execution time, and speed of algorithm convergence, the 14-node NSFNET network topology simulation experiment is implemented. The results show that when the channel contains 18 wavelengths, compared with the traditional KSP-FF algorithm, the blocking rate of this routing wavelength assignment algorithm is reduced by 0.06, and the resource utilization rate is increased by 0.02, but the execution time is increased. When the number of wavelengths exceeds 45, compared with KSP-FF, the proposed algorithm maintains the blocking rate and resource utilization, while the execution time begins to decrease. When the number of wavelengths is 58, compared with KSP-FF, the proposed algorithm's execution time is reduced by 0.07 ms. It can be seen that the proposed algorithm optimizes the routing and wavelength assignment.
























 DownLoad:
DownLoad: